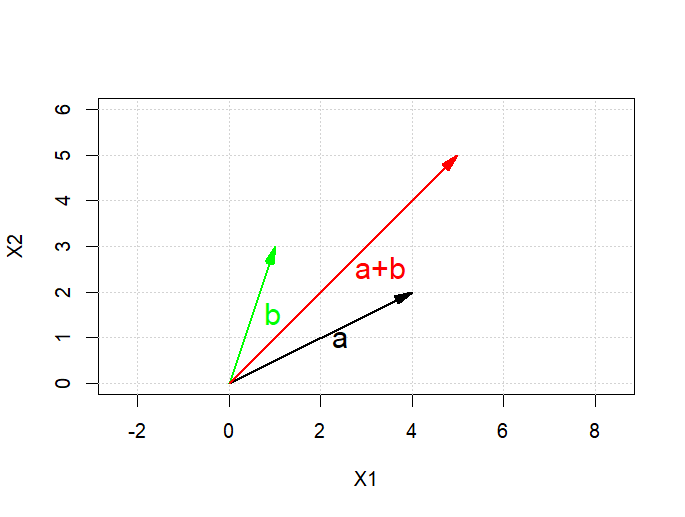
벡터의 시각화
> install.packages("matlib")
> library(matlib)
> xlim=c(0,6)
> ylim=c(0,6)
#x축과 y축의 범위를 설정하는 변수들입니다. 여기서는 (0, 6) 범위를 설정하여 그래프의 크기를 결정합니다.
> plot(xlim, ylim, type="n", xlab = "X1", ylab = "X2", asp=1)
> plot(): #그래프를 그리는 함수입니다. 여기서는 아무것도 표시하지 않고,
#x축과 y축의 범위만 설정한 후, 비어있는 그래프를 생성합니다.
> grid() #그래프에 격자를 추가하는 함수입니다.
>
> a=c(4,2)
> b=c(1,3)
>
> vectors(b,labels="b", pos.lab=4, frac.lab=.5, col="green")
> vectors(a,labels="a", pos.lab=4, frac.lab=.5)
> vectors(a+b,labels="a+b", pos.lab=4, frac.lab=.5, col="red")
-plot() 함수를 사용하여 그래프를 생성하는 부분입니다. 여기서 사용된 매개변수들의 의미는 다음과 같습니다:
- xlim, ylim: x축과 y축의 범위를 설정합니다. 여기서는 xlim 변수에 (0, 6) 범위를, ylim 변수에도 (0, 6) 범위를 설정하였습니다. 이는 그래프의 x축과 y축이 0부터 6까지의 범위를 가지도록 설정하는 것을 의미합니다.
- type="n": 이 매개변수는 그래프의 유형을 지정하는 것입니다. 여기서 "n"은 "none"을 의미하며, 데이터를 포함하지 않고 비어있는 그래프를 생성합니다. 이는 실제 데이터가 아니라 그래프의 구조를 설정하기 위한 것입니다.
- xlab, ylab: x축과 y축에 라벨을 추가하는 것을 지정합니다. 여기서는 "X1"과 "X2"라벨이 x축과 y축에 각각 추가됩니다.
- asp=1: 이 매개변수는 그래프의 종횡비(Aspect Ratio)를 설정합니다. 여기서는 1로 설정되어 있으므로, x축과 y축의 길이의 비율이 1:1이 되도록 그래프가 생성됩니다. 즉, 그래프가 정사각형 모양으로 보이도록 설정하는 것입니다.\
-pos.lab 및 frac.lab는 vectors() 함수의 옵션 중 일부입니다.
- pos.lab: "라벨"의 위치를 지정하는 매개변수입니다. 여기서는 숫자 4가 사용되었으며, 이것은 라벨이 벡터 끝에서부터 어느 정도 떨어진 위치에 표시되는지를 나타냅니다. 일반적으로 1은 벡터 시작점에 가깝고 2는 벡터 끝점에 가까운 위치를 의미합니다. 여기서 4는 끝점에서 시작점 쪽으로 이동하며, 끝점으로부터의 거리를 조절하는 역할을 합니다.
- frac.lab: "라벨"의 위치를 벡터의 어느 부분에 표시할지를 결정하는 상대적인 비율을 지정하는 매개변수입니다. 여기서는 0.5가 사용되었으며, 이것은 라벨이 벡터의 중간에 표시되도록 설정합니다. 예를 들어, 0은 벡터의 시작점에, 1은 벡터의 끝점에 라벨이 위치하도록 합니다. 따라서 0.5는 벡터의 중간에 라벨이 표시됩니다.
벡터의 길이
> #빗변의 길이
> x=c(3,5)
> y=c(1,2)
> y_x1=sqrt((3-1)^2+(5-2)^2)
> y_x1
[1] 3.605551
> y_x= x%*%y
> y_x
[,1]
[1,] 13
> sqrt(y_x)
[,1]
[1,] 3.605551
벡터의 각
-각은 곧 두 벡터간의 관계
-직각(90)=직교는 관계가 없다
-cos 세타가 0 or 180인 경우는 서로 관계가 깊다
벡터의 내적
-두 벡터의 크기(norm)과 각의 코사입 곱을 통한 연산
-실수 하나로 나옴
-각의 주는 의미와 마찬가지로 연관성을 표현
코사인 "각도"를 키울 수록 "코사인 값"을 계산하여 res행렬에 저장한 다음, 그 값을 시각화하고 0.7보다 작은 값을 가진 코사인의 각도를 반환
> res <- matrix(0, 980, 1)
> for (i in 1:980) {
+ res[i, 1] <- cos(i * pi / 180)
+ }
> plot(res, type = "l")
> which(res <= 0.7)
[1] 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
[28] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
[55] 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126
[82] 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153
[109] 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180
[136] 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207
[163] 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234
[190] 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261
[217] 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288
[244] 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 406
[271] 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433
[298] 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460
[325] 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487
[352] 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514
[379] 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541
[406] 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568
[433] 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595
[460] 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622
[487] 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649
[514] 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 766 767
[541] 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794
[568] 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821
[595] 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848
[622] 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875
[649] 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902
[676] 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929
[703] 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953 954 955 956
[730] 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980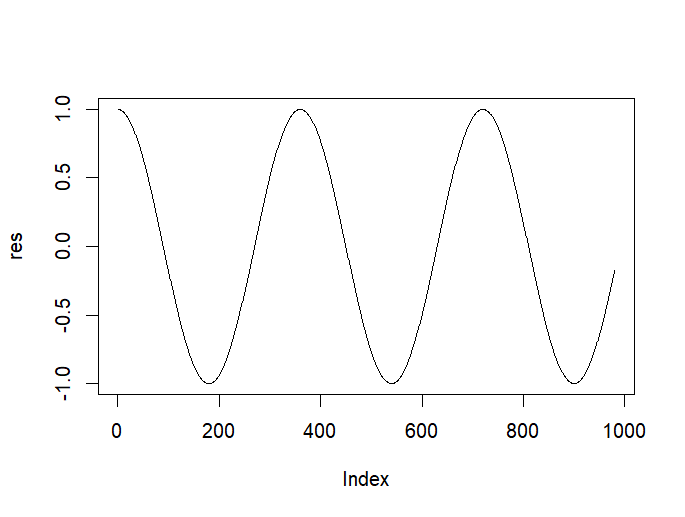
사영
-어떤 한 공간의 데이터를 다른 공간으로 보내는 것
-y정보에 x정보를 내리 꽂아 버리는 기술->y로 설명될 수 있는 x의 정보량
행렬
-n*p/p*g->열과 행이 맞아야 한다
- (N by p)*(p by N)
전치행렬
> mat=matrix(c(1,2,3,4), nrow=2)
> mat
[,1] [,2]
[1,] 1 3
[2,] 2 4
> t(mat)
[,1] [,2]
[1,] 1 2
[2,] 3 4-곱하기 할 때 편함
정방행렬
-정사각형 n*n
행렬식 determinant(ad-bc)
-정보의 양
> # 2x2 행렬 정의
> A <- matrix(c(1, 2, 3, 4), nrow = 2, byrow = TRUE)
>
> A
[,1] [,2]
[1,] 1 2
[2,] 3 4
>
> # 행렬식(det) 계산
> determinant <- det(A)
>
> # 결과 출력
> print(determinant)
[1] -2
역행렬 inverse
>install.packages("pracma")
>library("pracma")
> mat=matrix(c(1,2,3,4), nrow=2)
> mat
[,1] [,2]
[1,] 1 3
[2,] 2 4
> t(mat)
[,1] [,2]
[1,] 1 2
[2,] 3 4
> inv(mat)
[,1] [,2]
[1,] -2 1.5
[2,] 1 -0.5
> solve(mat)
[,1] [,2]
[1,] -2 1.5
[2,] 1 -0.5-inv/solve()함수 사용
-역수
TRACE(대각 행렬 원소들의 합)
-우선 알 필요는 없다 없다
벡터의 노름
> v=c(1,2,1)
> Norm(v, p=2)
[1] 2.44949
>
> # 두 벡터 정의
> a <- c(1, 2, 3)
> b <- c(4, 5, 6)
>
> # 각 벡터의 L2 norm 계산
> norm_a <- Norm(a, p = 2)
> norm_b <- Norm(b, p = 2)
>
> # 코사인 세타 계산
> cos_theta <- (t(a) %*% b) / (Norm(a, p = 2) * Norm(b, p = 2))
>
> print(cos_theta)
[,1]
[1,] 0.9746318-벡터의 거리
-메트릭스가 편하기는 하지만 대표값이나 강도를 알려면 노름이 편하다
-ㅣAㅣ
-p는 제곱
고유값과 고유벡터
> mat = matrix(c(5,25,35,25,155,175,35,175,325), ncol=3)
> mat
[,1] [,2] [,3]
[1,] 5 25 35
[2,] 25 155 175
[3,] 35 175 325
> eanalysis =eigen(mat, symmetric = T)#symmetric = TRUE
> eanalysis
eigen() decomposition
$values #고유값
[1] 438.7997639 45.6005209 0.5997152
$vectors #고유벡터
[,1] [,2] [,3]
[1,] -0.09848966 -0.05766723 0.99346579
[2,] -0.52858691 -0.84281026 -0.10132496
[3,] -0.84314629 0.53511248 -0.05252595
>
> t(eanalysis$vectors)%*%eanalysis$vectors
[,1] [,2] [,3]
[1,] 1.000000e+00 0.000000e+00 2.775558e-17
[2,] 0.000000e+00 1.000000e+00 4.510281e-17
[3,] 2.775558e-17 4.510281e-17 1.000000e+00
> det(mat)#정보의 양
[1] 12000
> prod(eanalysis$value)#고유값들의 곱을 의미한다
[1] 12000
>
> a=matrix(c(1,2,3,4,5,6), ncol=1)
> a
[,1]
[1,] 1
[2,] 2
[3,] 3
[4,] 4
[5,] 5
[6,] 6
> b=matrix(c(1,2,3,4,5,6), ncol=1)
> b
[,1]
[1,] 1
[2,] 2
[3,] 3
[4,] 4
[5,] 5
[6,] 6
> t(a)%*%b
[,1]
[1,] 91
> #메트릭스와 벡터는 다르다
=t(x)%*%x=단위행렬/1이된다/ 4.510281e-17이나 2.775...e..는 0에 가까운 매우 작은 숫자다
-고유벡터와 전치한 고유벡터의 곱은 단위행렬에 근접한 값으로 나온다
-그 의미는 고유벡터들이 서로 직교한다는 의미이다
- det(mat)=prod(eanalysis$value) 이건 무슨 의미?
- 행렬의 determinant(det): 행렬의 determinant는 부피 변화율을 나타내며, 행렬이 벡터를 변환할 때 부피의 변화를 결정합니다. 따라서 determinant는 해당 행렬의 크기와 구조에 대한 정보를 제공합니다.
- 고유값들의 곱(eigenvalues): 고유값들의 곱은 해당 행렬의 고유벡터들이 변환에서 어떻게 동작하는지를 나타냅니다. 고유값들은 행렬이 벡터를 변환할 때 벡터의 크기만을 변화시키고 방향을 유지하는데, 이 때 고유값들은 크기 변화율을 나타내며, 이 값들의 곱은 전체 변환의 크기 변화율을 나타냅니다.
-
따라서 행렬의 determinant(det)와 고유값들의 곱은 행렬의 변환 특성과 크기에 대한 중요한 정보를 제공합니다. 만약 행렬의 determinant가 0이 아니라면, 고유값들의 곱과 determinant는 서로 관련이 있습니다. 하지만 determinant가 0인 경우에는 추가적인 분석이 필요합니다.