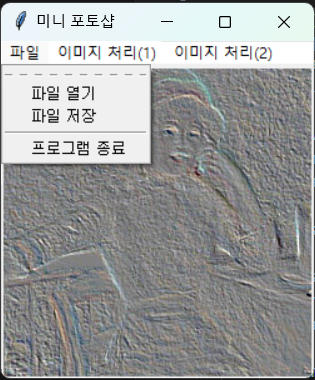
위젯은 위도창에 나올 수 있는 문자, 버튼, 체크박스, 라디오 버튼 등을 의미한다.
필수
Code10-01.py
from tkinter import *
window = Tk()
##이 부분에서 화면을 구성하고 처리##
window.mainloop() ##필수
기본적인 윈도창의 구성이다.
-tkinter는 gui 관련 보듈을 제공해주는 표준 위도 라이브러리이다.
-window = tk()르 통해 윈도창이 화면에 출련된다.
-window.mainloop()는 다양한 이벤트를 처리하는데 필요
Code10-02.py
from tkinter import *
window = Tk()
window.title("윈도우 연습")
window.geometry("400x100")
window.resizable(width = False, height = False) #크기 변동x
##이 부분에서 화면을 구성하고 처리##
window.mainloop() ##필수
레이블
Code10-03.py
from tkinter import *
window = Tk()
label1 = Label(window, text = "COOKBOOK~~Pytthon을")
label2 = Label(window, text = "열심히", font=("궁서체", 30), fg = "blue")
label3 = Label(window, text = "공부 중입니다.", bg = "magenta", width = 20, height=5, anchor = SE)
label1.pack()
label2.pack()
label3.pack()
window.mainloop() ##필수
-레이블 =문자를 표현하는 위젯
-Label(부모윈도, 옵션...)
-레이블 같은 위젯은 .pack()함수를 호출해야한다.
-anchor는 위젯의 위치
Code10-04.py
from tkinter import *
window = Tk()
photo = PhotoImage(file= "C:/tukdata/ch10/image/GIF/dog.gif")
label1 = Label(window, image = photo)
label1.pack()
window.mainloop() ##필수
-글자 대신 이미지가 들어갔다.
selfstudy10-4.py
from tkinter import *
window = Tk()
# 첫 번째 이미지
photo1 = PhotoImage(file="C:/tukdata/ch10/image/GIF/dog.gif")
label1 = Label(window, image=photo1)
label1.pack(side=LEFT)
# 두 번째 이미지
photo2 = PhotoImage(file="C:/tukdata/ch10/image/GIF/dog2.gif")
label2 = Label(window, image=photo2)
label2.pack(side=LEFT)
window.mainloop()
버튼
Code10-05.py
from tkinter import *
window = Tk()
button1 = Button(window, text = "파이썬 종료", fg = "red", command = quit)
button1.pack()
window.mainloop() ##필수
-마우스 버튼을 누르면 효과가 실행되는 위젯
-command 옵션은 버튼을 눌렀을때 지정한 작업을 처리할 수 있다.
Code10-06.py
from tkinter import *
from tkinter import messagebox
##함수 선언 부분##
def myFunc() :
messagebox.showinfo("강아지 버튼", "강아지가 귀엽죠? ^^")
##메인코드 부분##
window = Tk()
photo = PhotoImage(file= "C:/tukdata/ch10/image/GIF/dog2.gif")
button1 = Button(window, image = photo, command = myFunc)
button1.pack()
window.mainloop() ##필수
체크버튼
Code10-07.py
from tkinter import *
from tkinter import messagebox
window = Tk()
##함수 선언 부분##
def myFunc() :
if chk.get() == 0 :
messagebox.showinfo("", "체크버튼이 꺼졌어요.")
else :
messagebox.showinfo("", "체크버튼이 켜졌어요.")
##메인코드 부분##
chk = IntVar()
cb1 = Checkbutton(window, text = "클릭하세요", variable = chk ,command = myFunc)
cb1.pack()
window.mainloop() ##필수
-intvar함수는 정수형 타입의 변수 생성
-체크버튼을 키면 chk 1대입 끄면 0 대입
라디오버튼
Code10-08.py
from tkinter import *
window = Tk()
##함수 선언 부분##
def myFunc() :
if var.get() == 1 :
label1.configure(text = "파이썬")
elif var.get() ==2 :
label1.configure(text = "C++")
else :
label1.configure(text = "java")
##메인코드 부분##
var = IntVar()
rb1 = Radiobutton(window, text = "파이썬", variable = var, value=1, command = myFunc)
rb2 = Radiobutton(window, text = "C++", variable = var, value=2, command = myFunc)
rb3 = Radiobutton(window, text = "java", variable = var, value=3, command = myFunc)
label1 = Label(window, text = "선택한 언어 : ", fg = "red")
rb1.pack()
rb2.pack()
rb3.pack()
label1.pack()
window.mainloop() ##필수
정렬
Code10-09.py
from tkinter import *
window = Tk()
button1 = Button(window, text = "버튼1")
button2 = Button(window, text = "버튼2")
button3 = Button(window, text = "버튼3")
button1.pack(side=LEFT)
button2.pack(side=LEFT)
button3.pack(side=LEFT)
window.mainloop() ##필수
-pack() 함수 옵션에서 side = 사용하면 된다.
Code10-10.py
from tkinter import *
window = Tk()
btnList = [None]*3
for i in range(0, 3) :
btnList[i] = Button(window, text = "버튼" + str(i+1))
for btn in btnList :
# btn.pack(side = RIGHT)
btn.pack(side = RIGHT, fill =X, ipadx = 10, ipady = 10, padx = 10, pady = 10)
window.mainloop() ##필수
Code10-11.py
from tkinter import *
##전역 변수 선언 부분##
btnList = [None]*9
fnameList = ["honeycomb.gif", "icecream.gif", "jellybean.gif", "kitkat.gif", "lollipop.gif", "marshmallow.gif", "nougat.gif", "oreo.gif", "pie.gif"]
photoList = [None]*9
i,k=0,0
xPos,yPos = 0,0
num = 0
##메인 코드 부분##
window = Tk()
window.geometry("210x210")
for i in range(0, 9) :
photoList[i] = PhotoImage(file = "ch10/image/GIF/" + fnameList[i])
btnList[i] = Button(window, image=photoList[i])
for i in range(0, 3) :
for k in range(0,3) :
btnList[num].place(x = xPos, y = yPos)
num += 1
xPos += 70
xPos =0
yPos += 70
window.mainloop() ##필수
-수평 side = left or right
-수직 = top or bottom
-폭조정 fill = x
-여백 = padx= 10 or pady = 10
-내부여백 ipadx = 10
고정위치 -> .place() 함수 사용
selfstudy10-2.py
from tkinter import *
import random # 랜덤 모듈 임포트
# 전역 변수 선언 부분
btnList = [None] * 9
fnameList = ["honeycomb.gif", "icecream.gif", "jellybean.gif", "kitkat.gif", "lollipop.gif",
"marshmallow.gif", "nougat.gif", "oreo.gif", "pie.gif"]
photoList = [None] * 9
i, k = 0, 0
xPos, yPos = 0, 0
num = 0
# 리스트를 랜덤하게 섞음
random.shuffle(fnameList)
# 메인 코드 부분
window = Tk()
window.geometry("210x210")
for i in range(0, 9):
photoList[i] = PhotoImage(file="ch10/image/GIF/" + fnameList[i])
btnList[i] = Button(window, image=photoList[i])
for i in range(0, 3):
for k in range(0, 3):
btnList[num].place(x=xPos, y=yPos)
num += 1
xPos += 70
xPos = 0
yPos += 70
window.mainloop()
Code10-12.py
from tkinter import *
from time import *
# 전역 변수 선언 부분
frameList = ["jeju1.gif", "jeju2.gif", "jeju3.gif", "jeju4.gif", "jeju5.gif", "jeju6.gif", "jeju7.gif", "jeju8.gif", "jeju9.gif"]
photoList = [None] * 9
num = 0
# 함수 선언 부분
def clickNext():
global num
num += 1
if num > 8:
num = 0
photo = PhotoImage(file="ch10/image/GIF/" + frameList[num])
pLabel.configure(image=photo)
pLabel.image = photo
def clickPrev():
global num
num -= 1
if num < 0:
num = 8
photo = PhotoImage(file="ch10/image/GIF/" + frameList[num])
pLabel.configure(image=photo)
pLabel.image = photo
# 메인 코드 부분
window = Tk()
window.geometry("700x500")
window.title("사진 앨범 보기")
btnPrev = Button(window, text="« 이전", command=clickPrev)
btnNext = Button(window, text="다음 »", command=clickNext)
photo = PhotoImage(file="ch10/image/GIF/" + frameList[0])
pLabel = Label(window, image=photo)
btnPrev.place(x=250, y=10)
btnNext.place(x=400, y=10)
pLabel.place(x=15, y=50)
window.mainloop()
selfstudy10-3.py
from tkinter import *
from time import *
# 전역 변수 선언 부분
frameList = ["jeju1.gif", "jeju2.gif", "jeju3.gif", "jeju4.gif", "jeju5.gif",
"jeju6.gif", "jeju7.gif", "jeju8.gif", "jeju9.gif"]
photoList = [None] * 9
num = 0
# 함수 선언 부분
def clickNext():
global num
num += 1
if num > 8:
num = 0
updateImage()
def clickPrev():
global num
num -= 1
if num < 0:
num = 8
updateImage()
def updateImage():
# 이미지 업데이트
photo = PhotoImage(file="ch10/image/GIF/" + frameList[num])
pLabel.configure(image=photo)
pLabel.image = photo
# 파일명 업데이트
fileNameLabel.config(text=frameList[num])
# 메인 코드 부분
window = Tk()
window.geometry("700x500")
window.title("사진 앨범 보기")
btnPrev = Button(window, text="« 이전", command=clickPrev)
btnNext = Button(window, text="다음 »", command=clickNext)
photo = PhotoImage(file="ch10/image/GIF/" + frameList[0])
pLabel = Label(window, image=photo)
# 파일명 표시용 라벨 추가
fileNameLabel = Label(window, text=frameList[0], font=("Arial", 12))
fileNameLabel.place(x=320, y=15)
btnPrev.place(x=250, y=10)
btnNext.place(x=400, y=10)
pLabel.place(x=15, y=50)
window.mainloop()
마우스 이벤트 처리
def 이벤트처리함수(event):
#이 부분에 마우스 이벤트가 발생할 때 작동할 내용 작성
위젯.bind("마우스이벤트", 이벤트처리함수)
Code10-13.py
from tkinter import *
from tkinter import messagebox
#함수 선언 부분
def clickLeft(event):
messagebox.showinfo("마우스", "마우스 왼쪽 버튼이 클릭됨")
##이 부분에서 화면을 구성하고 처리##
window = Tk()
window.bind("<Button-1>", clickLeft)
window.mainloop() ##필수
Code10-14.py
from tkinter import *
from tkinter import messagebox
#함수 선언 부분
def clickImage(event):
messagebox.showinfo("마우스", "토끼에서 마우스가 클릭됨")
##이 부분에서 화면을 구성하고 처리##
window = Tk()
window.geometry("400x400")
photo = PhotoImage(file = "ch10/image/GIF/rabbit.gif")
label1 = Label(window, image = photo)
label1.bind("<Button>", clickImage)
label1.pack(expand = True, anchor = CENTER)
window.mainloop() ##필수
-label.bind로 이미지를 클릭할 때만 이벤트 처리된다(window.bind면 위젯 자체)
Code10-15.py
from tkinter import *
#함수 선언 부분
def clickMouse(event):
txt = ""
if event.num == 1:
txt += "마우스 왼쪽 버튼이 ("
elif event.num == 3:
txt += "마우스 오른쪽 버튼이 ("
txt += str(event.y) + "," + str(event.x) + ")에서 클릭됨"
label1.configure(text = txt)
#메인 코드 부분##
window = Tk()
window.geometry("400x400")
label1 = Label(window, text= "이곳이 바뀜")
window.bind("<Button>", clickMouse)
label1.pack(expand = True, anchor = CENTER)
window.mainloop() ##필수
키보드 이벤트 기본처리
Code10-16.py
from tkinter import *
from tkinter import messagebox
#함수 선언 부분
def keyEvent(event):
messagebox.showinfo("키보드 이벤트", "눌린 키 : " + chr(event.keycode))
#메인 코드 부분##
window = Tk()
window.bind("<Key>", keyEvent)
window.mainloop() ##필수
-.event.keycode에 눌려진 키의 숫자값이 chr()함수를 사용해서 문자로 변환시켰다
selfstudy10-4.py
from tkinter import *
from tkinter import messagebox
# 함수 선언 부분
def keyEvent(event):
# Shift 키와 화살표 키 조합에 따라 메시지 출력
if event.keycode == 37:
messagebox.showinfo("키보드 이벤트", "눌린 키 : Shift + 왼쪽 화살표")
elif event.keycode == 38:
messagebox.showinfo("키보드 이벤트", "눌린 키 : Shift + 위쪽 화살표")
elif event.keycode == 39:
messagebox.showinfo("키보드 이벤트", "눌린 키 : Shift + 오른쪽 화살표")
elif event.keycode == 40:
messagebox.showinfo("키보드 이벤트", "눌린 키 : Shift + 아래쪽 화살표")
# 메인 코드 부분
window = Tk()
# Shift와 각 화살표 키 조합에 대해 이벤트 바인딩
window.bind("<Shift-Left>", keyEvent)
window.bind("<Shift-Up>", keyEvent)
window.bind("<Shift-Right>", keyEvent)
window.bind("<Shift-Down>", keyEvent)
window.mainloop()
메뉴의 생성
메뉴자체 = Menu(부모윈도)
부모윈도.config(menu = 메뉴자체)
상위메뉴 = Menu(메뉴자체)
메뉴자체.add_cascade(label = "상위메뉴텍스트", menu = 상위메뉴)
상위메뉴.add_command(label = "하위메뉴1", command = 함수1)
상위메뉴.add_command(label = "하위메뉴2", command = 함수2)
Code10-17.py
from tkinter import *
window = Tk()
mainMenu = Menu(window) #메뉴자체 변수
window.config(menu = mainMenu) #생성한 메뉴 자체를 윈도창 메뉴로 지정
fileMenu = Menu(mainMenu) #상위 메뉴인 파일을 생성하고 메뉴 자체에 부착
mainMenu.add_cascade(label="파일", menu = fileMenu)
fileMenu.add_command(label="열기")#하위메뉴
fileMenu.add_separator()
fileMenu.add_command(label="종료")
window.mainloop() ##필수
Code10-18.py
from tkinter import *
from tkinter import messagebox
#함수 선언 부분
def func_open():
messagebox.showinfo("메뉴선택", "열기 메뉴를 선택함")
def func_exit():
window.quit()
window.destroy()
#메인 코드 부분##
window = Tk()
mainMenu = Menu(window)
window.config(menu = mainMenu)
fileMenu = Menu(mainMenu)
mainMenu.add_cascade(label="파일", menu = fileMenu)
fileMenu.add_command(label="열기", command = func_open)
fileMenu.add_separator()
fileMenu.add_command(label="종료", command= func_exit)
window.mainloop() ##필수
-add_command()함수: 무언가 작동
대화상자의 생성과 사용
Code10-19.py
from tkinter import *
from tkinter.simpledialog import*
#함수 선언 부분
window = Tk()
window.geometry("400x100")
label1 = Label(window, text = "입력된 값")
label1.pack()
value = askinteger("확대배수", "주사위 숫자(1~6)을 입력하세요", minvalue = 1, maxvalue = 6)
label1.configure(text = str(value))
window.mainloop() ##필수
-tkinter.simpledialog모듈 임포트
-askinteger("제목", "내용", 옵션)
숫자나 문자를 입력받으려면 tkinter.simpledialog 모듈을 입포트한 후 askinteger(), askfloa(), askstring()함수 등을 사용한다.
Code10-20.py
from tkinter import *
from tkinter.filedialog import*
#함수 선언 부분
window = Tk()
window.geometry("400x100")
label1 = Label(window, text = "선택된 파일 이름")
label1.pack()
filename = askopenfilename(parent=window, filetypes=(("GIF 파일", "*.gif"), ("모든 파일", "*.*")))
label1.configure(text = str(filename))
window.mainloop() ##필수
-tkinter.filedialog 임포트
-askopenfilename()함수
파일을 열거나 저장할 때 나타나는 대화상자는 tkinter.filedilog 모듈을 임포트한 후 askopenfilename() 또는 asksaveasfile()함수를 사용한다.
Code10-21.py
from tkinter import *
from tkinter.filedialog import*
#함수 선언 부분
window = Tk()
window.geometry("400x100")
label1 = Label(window, text = "선택된 파일 이름")
label1.pack()
saveFp = asksaveasfile(parent=window, mode= "w", defaultextension = ".jpg", filetypes = (("jpg 파일", "*.jpg;*.jpeg"), ("모든 파일", "*.*")))
label1.configure(text = saveFp)
saveFp.close() ##필수
-asksaveasfile()->다른 이름으로 저장
-mode "W"는 쓰기
Code10-22.py
from tkinter import *
from tkinter.filedialog import *
# 함수 선언 부분
def func_open():
filename = askopenfilename(parent=window, filetypes=(("GIF 파일", "*.gif"), ("모든 파일", "*.*")))
photo = PhotoImage(file=filename)
pLabel.configure(image=photo)
pLabel.image = photo
def func_exit():
window.quit()
window.destroy()
# 메인 코드 부분
window = Tk()
window.geometry("500x500")
window.title("명화 감상하기")
photo = PhotoImage()
pLabel = Label(window, image=photo)
pLabel.pack(expand=1, anchor=CENTER)
mainMenu = Menu(window)
window.config(menu=mainMenu)
fileMenu = Menu(mainMenu)
mainMenu.add_cascade(label="파일", menu=fileMenu)
fileMenu.add_command(label="파일 열기", command=func_open)
fileMenu.add_separator()
fileMenu.add_command(label="프로그램 종료", command=func_exit)
window.mainloop()
selfstudy10-5.py
from tkinter import *
from tkinter.filedialog import *
# 함수 선언 부분
def func_open():
filename = askopenfilename(parent=window, filetypes=(("GIF 파일", "*.gif"), ("모든 파일", "*.*")))
if filename:
global photo
photo = PhotoImage(file=filename)
grayscale_image(photo)
pLabel.configure(image=photo)
pLabel.image = photo
def grayscale_image(photo):
width = photo.width()
height = photo.height()
for x in range(width):
for y in range(height):
r, g, b = photo.get(x, y)
gray = (r + g + b) // 3
# 픽셀을 회색으로 설정
photo.put("#%02x%02x%02x" % (gray, gray, gray), (x, y))
def func_exit():
window.quit()
window.destroy()
# 메인 코드 부분
window = Tk()
window.geometry("500x500")
window.title("명화 감상하기")
photo = PhotoImage()
pLabel = Label(window, image=photo)
pLabel.pack(expand=1, anchor=CENTER)
mainMenu = Menu(window)
window.config(menu=mainMenu)
fileMenu = Menu(mainMenu)
mainMenu.add_cascade(label="파일", menu=fileMenu)
fileMenu.add_command(label="파일 열기", command=func_open)
fileMenu.add_separator()
fileMenu.add_command(label="프로그램 종료", command=func_exit)
window.mainloop()