3주차 과제
-기술과제
호스팅이 무엇인지 ?
AWS 회원가입, EC2서비스 프리티어(1년공짜) 인스턴스 생성해보기 (OS아무거나, Ubuntu 추천)
SSH가 무엇인지 ?
SSH가지고 생성한 EC2서비스 연결까지 해보기
-->https://eatitstory.tistory.com/m/8 다른 글에 작성
-코드과제
BeautifulSoup4 모듈 (HTML DOM접근을 도와주는 모듈)
requests모듈을 이용을해서 html을 가져온다음
BS모듈에가 html을 준다
내가 원하는 부분을 선택해서 원하는데이터 불러와서 print했을때 잘 찍혀나오게끔 해보기
*코드과제
(1)
import requests
from bs4 import BeautifulSoup
저번에 배운 requests 모듈과 같은 방식으로 패키지에서 다운 받아 이번에 사용하게 될 beautifulSoup모듈을 설치해준다.
설치 후 아래와 같이 모듈을 가져온다.
(2)
해외축구 : 네이버 스포츠
스포츠의 시작과 끝!
sports.news.naver.com
네이버 해외축구 사이트의 html을 가져온 후 data변수에 집어 넣어준다.
BeautifulSoup함수(BeautifulSoup(html 문자열, parsing 방법))를 활용하여 data를 파싱해준다.
(파싱이란 파이썬이 html을 알아듣기 편하게 바꿔주는 방식)
data = requests.get('https://sports.news.naver.com/wfootball/index')
soup = BeautifulSoup(data.text, 'html.parser')
(3)
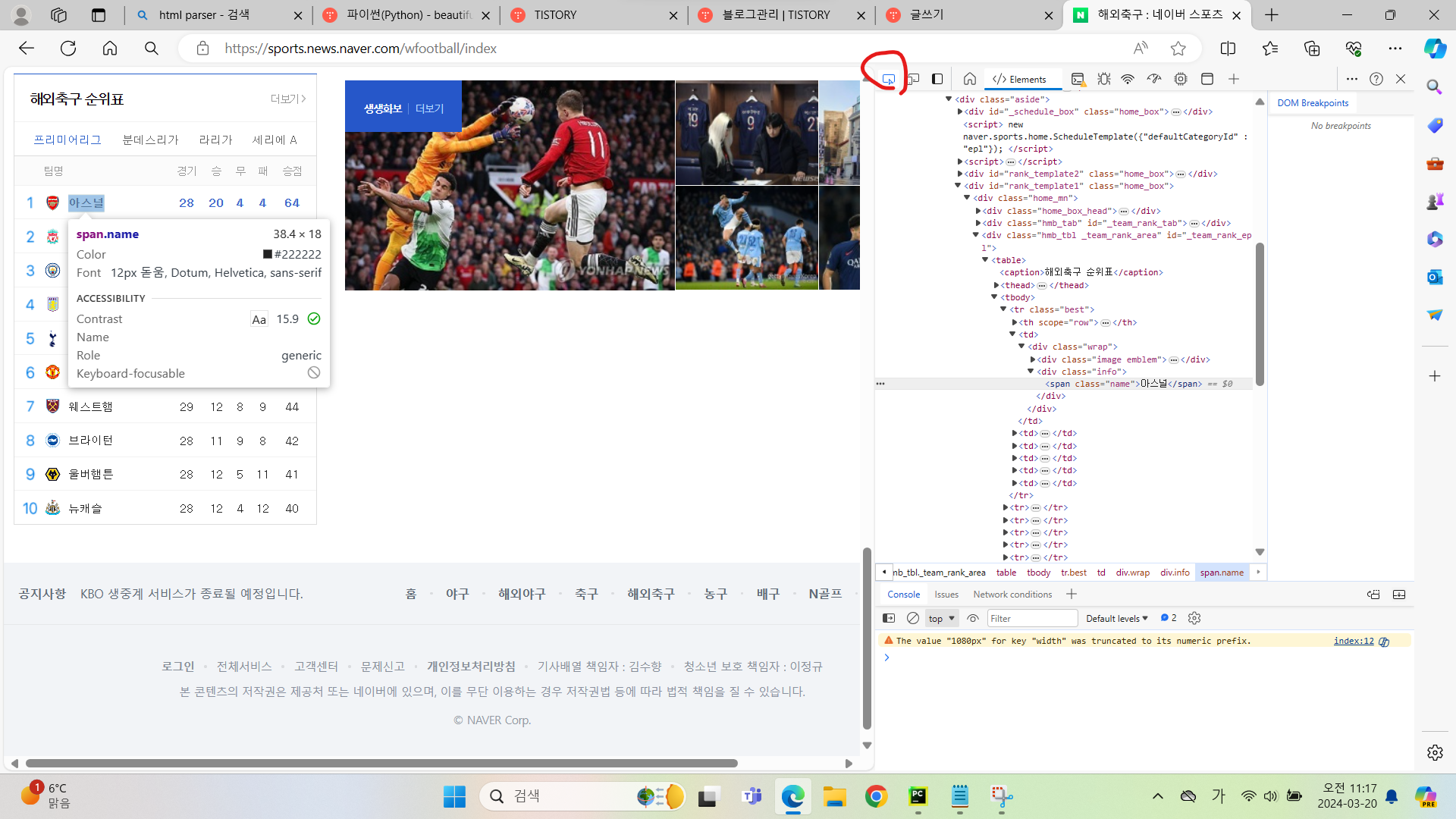
사이트 들어가서 f12 눌러서 개발자도구에서 빨간 동그라미 눌러 아스날에 커서 갔다대면 소스가 보인다.
copy sector로 소스를 복사한다.

tbody 아래에 tr들이 순위표에 있는 팀들의 소스가 있다.
(4)
soccer_rank = soup.select('#_team_rank_epl > table > tbody > tr')
우선 soccer_rank에 soup.select()란 함수를 사용하여 requests로 가져온 html 중 해외축구 순위표에 있는 데이터들이 담겨있는 tr class를 찾아온다.
(5)
for tr in soccer_rank:
span = tr.select_one("td > div > div.info > span")
if span:
print(span.text)
else:
print("Span not found")tr.select_one(select와 다르게 하나의 class를 찾는다)을 이용하여 다양한 데이터가 담겨있는 tr에서 순위표에 있는 팀들의 이름이 있는 span class 가져와 출력한다.
(6)
import requests
from bs4 import BeautifulSoup
data = requests.get('https://sports.news.naver.com/wfootball/index')
soup = BeautifulSoup(data.text, 'html.parser')
soccer_rank = soup.select('#_team_rank_epl > table > tbody > tr')
for tr in soccer_rank:
span = tr.select_one("td > div > div.info > span")
if span:
print(span.text)
else:
print("Span not found")
# _team_rank_epl > table > tbody > tr:nth-child(2) > td:nth-child(2) > div > div.info > span ->>2위 리버풀 주소
#각 팀별로 나눠지는 tr들까지만 select하고/ 각 tr에서 이름이 담겨있는 span class를 가져와 출력하기

'Development > Back' 카테고리의 다른 글
| 나만의 챗봇 만들어 보기(Open AI 어시스턴스 실습) (1) | 2024.05.19 |
|---|---|
| 백엔드 서버 구현해보기(flask 실습) (0) | 2024.05.12 |
| openai(chat gpt) api 활용 (0) | 2024.04.14 |
| 웹사이트 구성하는 방법(Node.js) (1) | 2024.04.07 |
| http 메소드 및 requests 모듈 사용 (0) | 2024.03.15 |