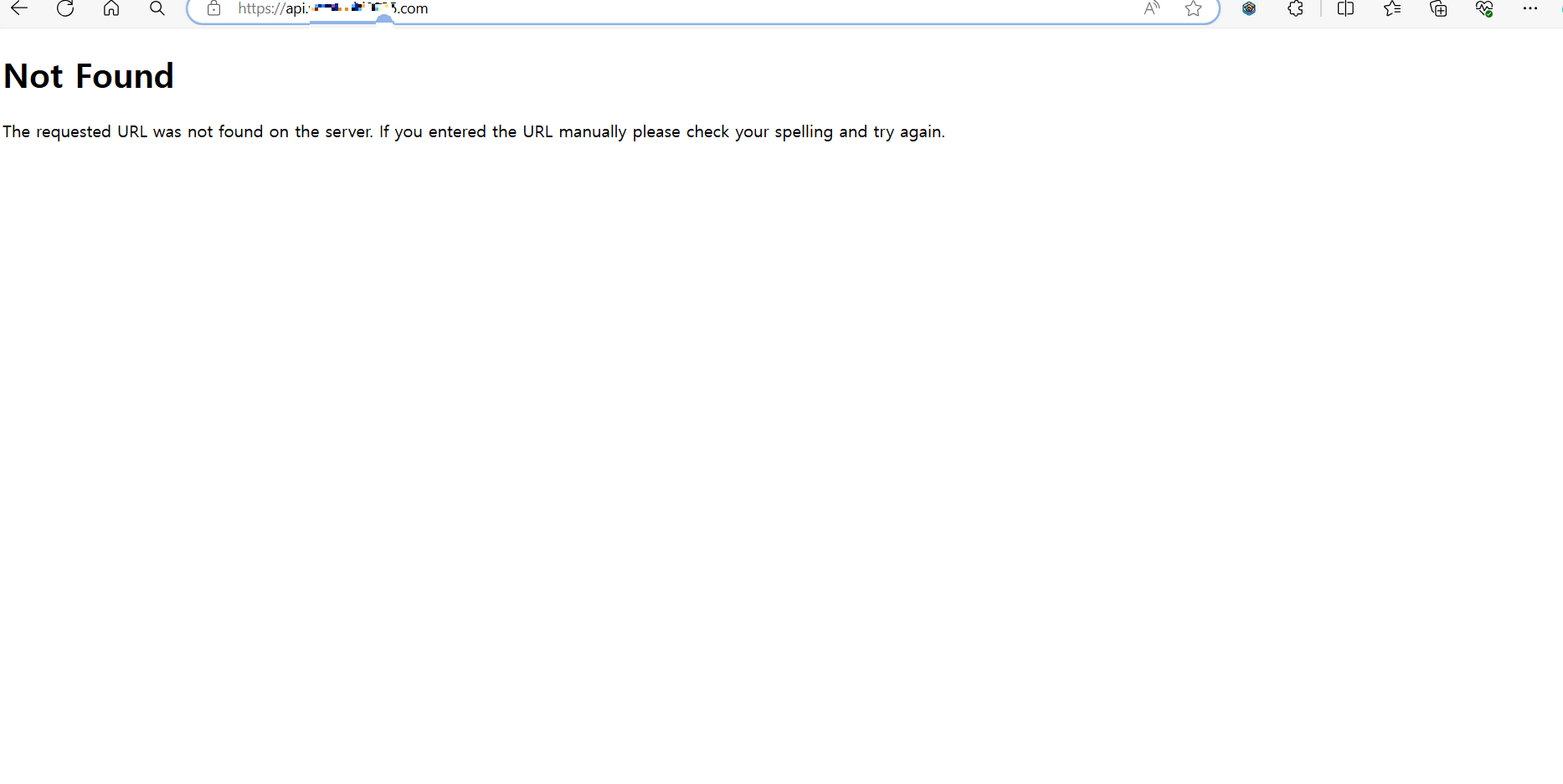
도메인 포워딩: cafe24에서 구매한 도메인이 다른 웹사이트(aws인스턴스 퍼블릭 IPv4 DNS)로 이동 시켜주는 기능
네임서버 관리: 호스트ip 수정으로 aws public ip를 수정하고 서브 도메인으로 (api.내 도메인)으로 추가
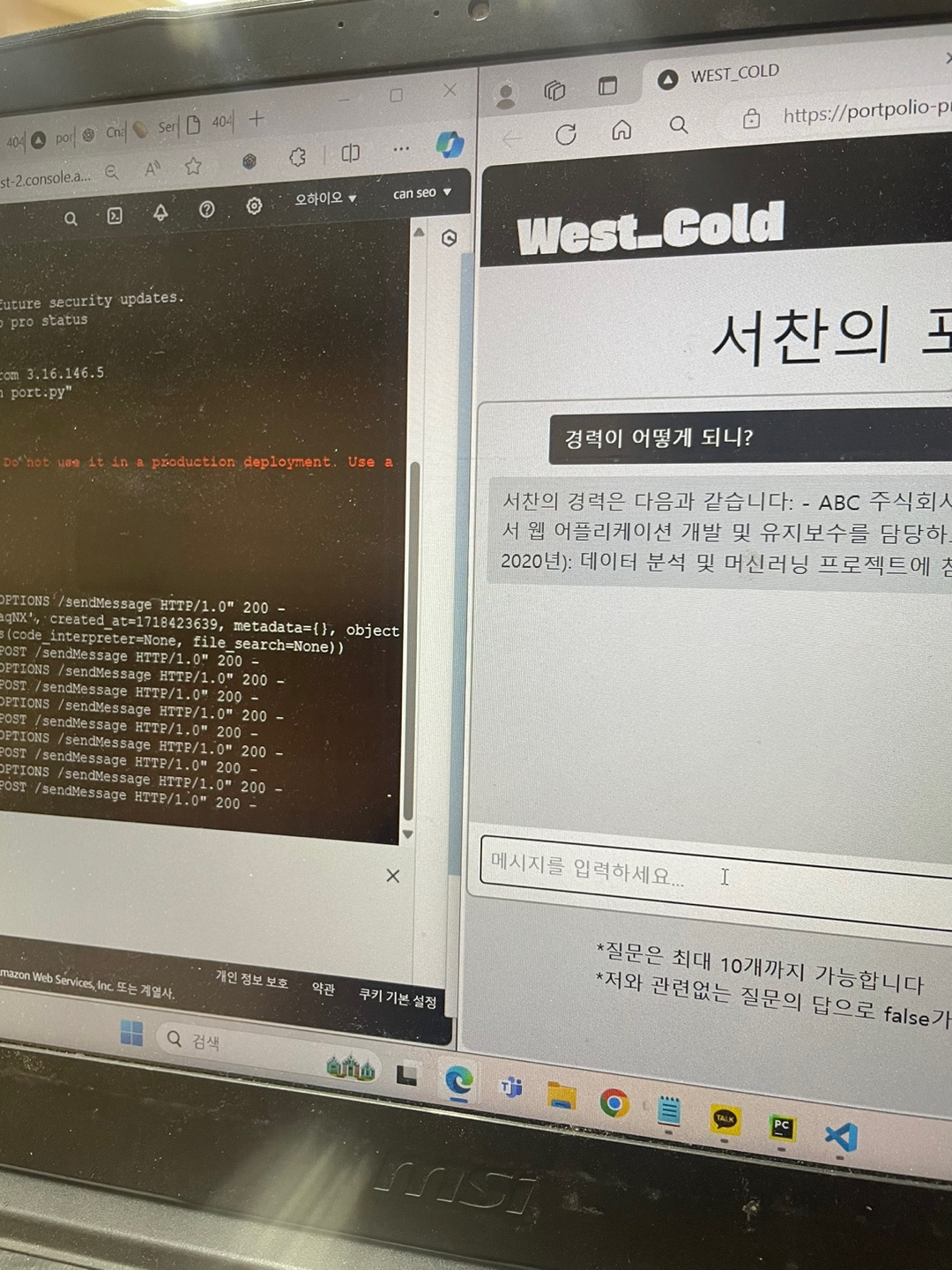
#로컬호스트 말고 이제부터 사용할 내 서브 도메인을 활용해서 통신이 가능하게
#요청하는 프론트엔드 서버 코드 수정
const response = await axios.post('https://api.내 도메인/sendMessage', {
user_input: inputValue
});
#https s!!주의 이거 빼먹어서 개고생함
Let's Encrypt Let's Encrypt는 무료의 TLS/SSL 인증서를 쉽게 가져오고 설치할 수 있는 방법을 제공하는 CA(인증 기관)으로, 웹 서버에서 암호화된 HTTPS를 사용할 수 있다. 이러한 방법은 사용자에게 Certbot라는 소프트웨어를 제공함으로써 구현할 수 있게 한다.
(2) Nginx 설정 파일 수동 업데이트 Nginx 기본 설정 파일에 들어가서 인증서를 적용할 도메인 이름을 설정합니다.
sudo nano /etc/nginx/sites-available/default
server {
listen 80;
server_name api.내 도메인;
location / {
proxy_pass http://127.0.0.1:5000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 원래 클라이언트 IP 주소를 전달합니다.
proxy_set_header X-Original-IP $remote_addr;
}
if ($scheme != "https") {
return 301 https://$host$request_uri;
}
}
server {
listen 443 ssl;
server_name api.내 도메인;
ssl_certificate /etc/letsencrypt/live/api.westcold0035.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/api.westcold0035.com/privkey.pem;
location / {
proxy_pass http://127.0.0.1:5000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 원래 클라이언트 IP 주소를 전달합니다.
proxy_set_header X-Original-IP $remote_addr;
}
}
Chat GPT의 도움을 받아 전체 과정 요약
80번 포트에서 HTTP 요청 수신:
server_name api.내 도메인;에 도메인 이름을 설정한다.
location / 블록은 모든 요청을 내부 서버(로컬호스트)로 프록시한다.
proxy_set_header 지시어를 사용해 클라이언트의 원본 요청 정보를 보존한다.
if ($scheme != "https") { return 301 https://$host$request_uri; } 구문을 통해 HTTP 요청을 HTTPS로 리다이렉트한다.
443번 포트에서 HTTPS 요청 수신:
listen 443 ssl;을 통해 SSL을 사용하는 443 포트에서 요청을 수신한다.
ssl_certificate와 ssl_certificate_key 지시어를 사용해 Let's Encrypt SSL 인증서를 적용한다.
location / 블록은 HTTP와 동일하게 모든 요청을 내부 서버(로컬호스트)로 프록시한다.
proxy_set_header 지시어를 사용해 클라이언트의 원본 요청 정보를 보존한다.
상세 설명
HTTP 요청 처리 (80번 포트)
HTTP 요청 수신: 서버는 80번 포트에서 HTTP 요청을 수신한다.
프록시 설정: 들어오는 모든 요청은 http://127.0.0.1:5000으로 프록시된다. 이는 로컬에서 동작하는 백엔드 애플리케이션을 의미한다.
헤더 설정: proxy_set_header 지시어를 통해 원래의 호스트, 클라이언트 IP 주소, 전달된 포워드 정보를 백엔드로 전달한다.
HTTP -> HTTPS 리다이렉션: 요청이 HTTP인 경우, Nginx는 해당 요청을 HTTPS로 리다이렉트한다. 이는 모든 트래픽을 암호화된 HTTPS로 강제하여 보안을 강화한다.
HTTPS 요청 처리 (443번 포트)
HTTPS 요청 수신: 서버는 443번 포트에서 SSL을 사용하는 HTTPS 요청을 수신한다.
SSL 인증서 설정: Let's Encrypt에서 발급받은 SSL 인증서와 개인 키를 사용하여 연결을 암호화한다.
프록시 설정: 들어오는 모든 HTTPS 요청은 http://127.0.0.1:5000으로 프록시된다.
헤더 설정: HTTP와 동일하게 원래의 호스트, 클라이언트 IP 주소, 전달된 포워드 정보를 백엔드로 전달한다.
설정 파일을 적용하기 위해 Nginx를 다시 로드해줍니다.
sudo systemctl reload nginx
(3) SSL 인증서 받기 Certbot은 다양한 플러그인을 통해 SSL 인증서를 획득하는 다양한 방법을 제공 Nginx플러그인은 필요할 때마다 Nginx를 재구성하고 구성을 다시 로드 이제 원하는 도메인을 지정해서 Nginx플러그인을 통해 인증서를 획득 이후 알림설정이 나오는데 다 ok해줬다
$ sudo certbot --nginx
Please enter the domain name(s) you would like on your certificate (comma and/or space separated) (Enter 'c' to cancel): api.your-domain.com
nginx는 내 컴퓨터가 서버가 되게 해주는 소프트웨어 -클라이언트와 WAS사이에서 서빙 및 매니징을 담당하는 역할을 수행 -정적인 요소를 was에 넘어가기 전 미리 서빙해줌
was란 서버의 동적인 요소를 전문적으로 처리해주는 서버.
Nginx를 사용하는 이유: 1. 리버스 프록시(보안 강화): Nginx는 보안을 강화하는 역할을 한다. 클라이언트와 직접 통신하는 대신 Nginx를 통해 요청을 받아들이면 서버의 IP 주소를 숨길 수 있어 보안을 강화할 수 있다( 한마디로 말하면 클라이언트는 가짜 서버에 요청(request)하면, 프록시 서버가 배후 서버(reverse server)로부터 데이터를 가져오는 역할을 한다 )
2. 로드 밸런싱(부하 분산): Nginx는 요청을 여러 백엔드 서버로 분산하여 부하를 분산할 수 있다. 이를 통해 서버의 안정성과 성능을 향상시킬 수 있다.
3. 캐싱(정적 파일 서빙): Nginx는 정적 파일(HTML, CSS, JavaScript 등)을 효과적으로 서빙하는 데 사용된다. 이렇게 하면 백엔드 서버가 동적 콘텐츠에만 집중할 수 있고, 정적 파일 서빙은 Nginx가 처리하게 된다.(vercel로 프론트엔드 파일을 처리햇으니 3번은 굳이 지금은 필요없긴 하다)
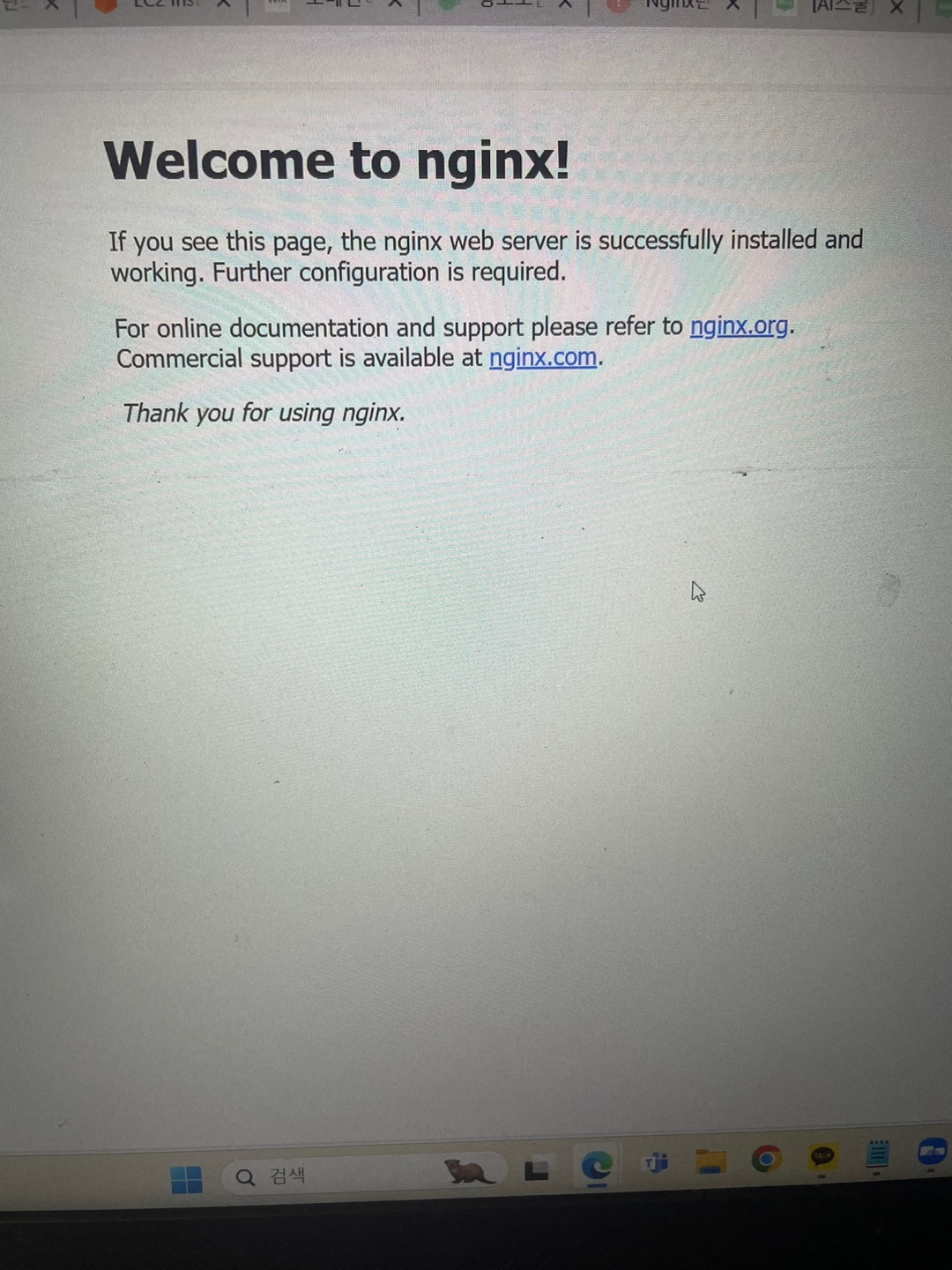
nginx를 업데이트하고 설치함
sudo apt update
sudo apt install nginx -y
nginx를 시작하고 부팅 시 자동으로 시작되도록 설정
sudo systemctl start nginx
sudo systemctl enable nginx
nginx 상태를 확인
sudo systemctl status nginx
openai api를 활용하면 토큰이 소모가 되는데 이게 사용량이 많으면 돈이 많이 깨진다 잘못하면 누가 마음 먹고 쓸모없는 채팅으로 내 토큰을 소모되게 할 수 있다 이를 해결하기 위해 여러 방법을 사용하여 보안을 구축해보았다.
1.검색어에 나의 대한 질문만 할 수 있게 설정
# 허용되는 키워드 목록
allowed_keywords = ["서찬", "찬", "너", "운영자"]
if any(keyword in user_input for keyword in allowed_keywords):
#생략
else:
return jsonify({"description": "입력값에 '서찬', '찬', '너', '운영자' 중 하나라도 포함되어야만 실행됩니다."})
2.각 ip마다 질문의 갯수를 제한하여 관리(+하루가 지나면 다시 초기화)
# 제한할 요청 수
REQUEST_LIMIT = 1 # 테스트 목적으로 1로 설정 (원래는 10개)
# IP 주소별 요청 횟수를 저장하는 사전
request_counts = defaultdict(lambda: {'count': 0, 'last_request': None})
def reset_request_count(ip):
request_counts[ip]['count'] = 0
request_counts[ip]['last_request'] = datetime.now()
def is_new_day(last_request):
return datetime.now() - last_request > timedelta(seconds=10) # 테스트 목적으로 10초로 설정 (원래는 days=1)
@app.route('/sendMessage', methods=['POST'])
def send_message():
data = request.get_json()
user_input = data.get('user_input')
#사용자 ip 가져오기
ip = request.remote_addr
# 요청 횟수 가져오기
request_data = request_counts[ip]
count = request_data['count']
last_request = request_data['last_request']
# 하루가 지났는지 확인하여 요청 횟수 초기화
if last_request is None or is_new_day(last_request):
reset_request_count(ip)
if count >= REQUEST_LIMIT:
return jsonify({"description": "질문이 초과했습니다ㅠㅠ"})
else:
request_counts[ip]['count'] += 1
request_counts[ip]['last_request'] = datetime.now()
-중간에 질문이 데이터 베이스에 저장하는데 쓰레드에 여러 질문이 들어와 저장이 안되고 또한 질문의 답 출력하는데 오류가 나길래 쓰레드를 각ip마다 주었다
# IP 주소별 스레드 ID를 저장하는 사전
thread_ids = {}
# 새로운 스레드 생성 함수
def create_new_thread():
response = client.beta.threads.create()
# response의 구조를 출력해보자
print(response)
# response 객체의 속성에 맞게 접근
return response.id
# sendMessage 라우터
@app.route('/sendMessage', methods=['POST'])
def send_message():
data = request.get_json()
user_input = data.get('user_input')
ip = request.remote_addr
# 요청 횟수 가져오기
request_data = request_counts[ip]
# IP 주소별 스레드 ID 가져오기
if ip not in thread_ids:
thread_id = create_new_thread()
thread_ids[ip] = thread_id
else:
thread_id = thread_ids[ip]
# AI 응답 가져오기
ai_response = get_ai_response(user_input, thread_id)
질문이 초과되면 초과되었다는 출력값을 주었다
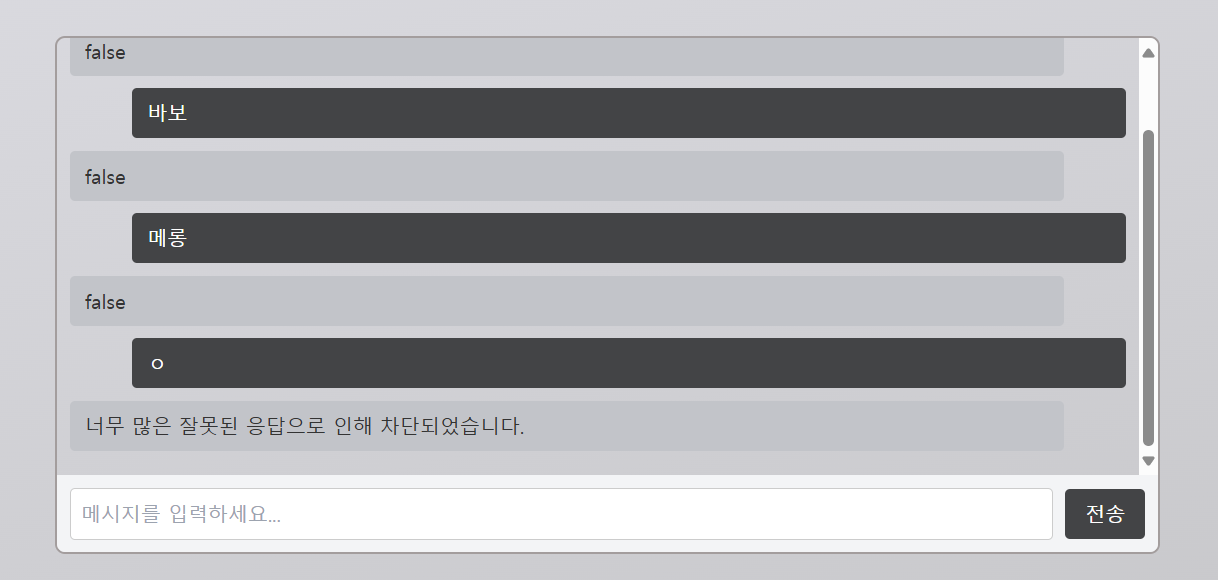
3. 잘못된 질문을 계속하면 차단하기
인스트럭션에 "서찬에 대한 질문이 아니면 "false" 라고만 대답해줘"라는 명령을 주어 false가 3번 이상 나오면 더 이상 opanai api가 실행되지 않게 설정해준다
request_counts = defaultdict(lambda: {'count': 0, 'last_request': None, 'false_count': 0})
def reset_request_count(ip):
request_counts[ip]['count'] = 0
request_counts[ip]['last_request'] = datetime.now()
request_counts[ip]['false_count'] = 0
@app.route('/sendMessage', methods=['POST'])
def send_message():
data = request.get_json()
user_input = data.get('user_input')
ip = request.remote_addr
# 요청 횟수 가져오기
request_data = request_counts[ip]
count = request_data['count']
last_request = request_data['last_request']
false_count = request_data['false_count']
# false_count가 3 이상이면 차단
if false_count >= 3:
return jsonify({"description": "너무 많은 잘못된 응답으로 인해 차단되었습니다."})
else:
# AI 응답 가져오기
ai_response = get_ai_response(user_input, thread_id)
# 'False' 응답 횟수 증가
if ai_response.strip().lower() == 'false':
request_counts[ip]['false_count'] += 1
4.데이터베이스에 사용자가 어떤 질문을 하는지와 어떤 사용자가 어떤 질문을 하는지 확인하게 사용자 ip를 저장하기
from openai import OpenAI
import time
from flask import Flask, request, jsonify
from flask_cors import CORS
import pymysql
from collections import defaultdict
from datetime import datetime, timedelta
# MySQL 데이터베이스 연결 설정 함수
def get_database_connection():
return pymysql.connect(host="localhost", user="root", password="", db="", charset="")
# 데이터베이스에 저장
try:
db_connection = get_database_connection()
cursor = db_connection.cursor()
query = "INSERT INTO portpolio.portpolio_input (ip, comments, answer) VALUES (%s, %s, %s)"
cursor.execute(query, (str(ip), user_input, ai_response))
db_connection.commit()
return jsonify({"description": ai_response})
except Exception as e:
return jsonify({"description": "데이터 저장 중 오류가 발생하였습니다: " + str(e)})
finally:
cursor.close()
db_connection.close()
-전체 코드
(검색어를 미리 설정 하는 건 비효율적이라는 피드백을 받아 수정->새로운 로직)
from openai import OpenAI
import time
from flask import Flask, request, jsonify
from flask_cors import CORS
import pymysql
from collections import defaultdict
from datetime import datetime, timedelta
app = Flask(__name__)
CORS(app) # 모든 출처에서의 요청을 허용합니다.
# OpenAI API 키 설정
client = OpenAI(api_key="")
# 제한할 요청 수
REQUEST_LIMIT = 5 # 테스트 목적으로 1로 설정 (원래는 10개)
# IP 주소별 요청 횟수를 저장하는 사전
request_counts = defaultdict(lambda: {'count': 0, 'last_request': None, 'false_count': 0})
# IP 주소별 스레드 ID를 저장하는 사전
thread_ids = {}
def reset_request_count(ip):
request_counts[ip]['count'] = 0
request_counts[ip]['last_request'] = datetime.now()
request_counts[ip]['false_count'] = 0
def is_new_day(last_request):
return datetime.now() - last_request > timedelta(seconds=50) # 테스트 목적으로 5초로 설정 (원래는 days=1)
# MySQL 데이터베이스 연결 설정 함수
def get_database_connection():
return pymysql.connect(host="", user="t", password="", db="", charset="")
# 새로운 스레드 생성 함수
def create_new_thread():
response = client.beta.threads.create()
# response의 구조를 출력해보자
print(response)
# response 객체의 속성에 맞게 접근
return response.id
# AI 응답을 가져오는 함수
def get_ai_response(user_input, thread_id):
try:
assistant_id = ""
message = client.beta.threads.messages.create(
thread_id,
role="user",
content=user_input,
)
run = client.beta.threads.runs.create(
thread_id=thread_id,
assistant_id=assistant_id,
)
run_id = run.id
while True:
run = client.beta.threads.runs.retrieve(
thread_id=thread_id,
run_id=run_id,
)
if run.status == "completed":
break
else:
time.sleep(2)
thread_messages = client.beta.threads.messages.list(thread_id)
ai_response = thread_messages.data[0].content[0].text.value
return ai_response
except Exception as e:
return str(e)
# sendMessage 라우터
@app.route('/sendMessage', methods=['POST'])
def send_message():
data = request.get_json()
user_input = data.get('user_input')
ip = request.remote_addr
# 요청 횟수 가져오기
request_data = request_counts[ip]
count = request_data['count']
last_request = request_data['last_request']
false_count = request_data['false_count']
# 하루가 지났는지 확인하여 요청 횟수 초기화
if last_request is None or is_new_day(last_request):
reset_request_count(ip)
# false_count가 3 이상이면 차단
if false_count >= 3:
return jsonify({"description": "너무 많은 잘못된 응답으로 인해 차단되었습니다."})
# 요청 횟수 확인
if count >= REQUEST_LIMIT:
return jsonify({"description": "질문이 초과했습니다ㅠㅠ"})
# 요청 횟수 증가
request_counts[ip]['count'] += 1
request_counts[ip]['last_request'] = datetime.now()
# IP 주소별 스레드 ID 가져오기
if ip not in thread_ids:
thread_id = create_new_thread()
thread_ids[ip] = thread_id
else:
thread_id = thread_ids[ip]
# AI 응답 가져오기
ai_response = get_ai_response(user_input, thread_id)
# 'False' 응답 횟수 증가
if ai_response.strip().lower() == 'false':
request_counts[ip]['false_count'] += 1
# 데이터베이스에 저장
try:
db_connection = get_database_connection()
cursor = db_connection.cursor()
query = "INSERT INTO portpolio.portpolio_input (ip, comments, answer) VALUES (%s, %s, %s)"
cursor.execute(query, (str(ip), user_input, ai_response))
db_connection.commit()
return jsonify({"description": ai_response})
except Exception as e:
return jsonify({"description": "데이터 저장 중 오류가 발생하였습니다: " + str(e)})
finally:
cursor.close()
db_connection.close()
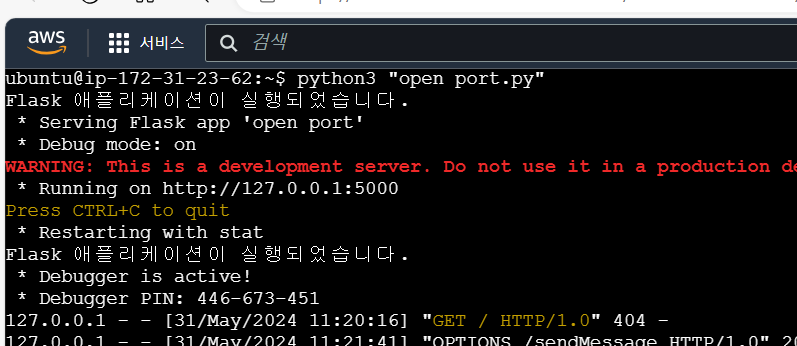
if __name__ == '__main__':
print("Flask 애플리케이션이 실행되었습니다.")
app.run(debug=True)
로직의 순서
하루마다 검색어 초기화->false 3번 했는지->ip마다 요청횟수->ip마다 쓰레드 만들기->ai에게 질문
이번 과제를 하며 느낀점 -사실 코딩 할 때 chatgpt한테 물어보는 경우가 많은데 아무리 편하다해도 조금 복잡한 로직은 오류가 많이 나서 시간이 오래 걸렸다. 그러나 한번 천천히 코드 읽어가면서 로직?을 이해하며 수정하니 30분이면 끝나는 경우도 많았다. 이를 통해 chatgpt에게 물어보기 전 먼저 내가 그 로직을 구상 + 코드가 나오면 로직을 읽는 버릇이 필요하다 느낌
from openai import OpenAI
import time
# OpenAI API 키 설정
client = OpenAI(api_key="")
#assistant 생성
assistant = client.beta.assistants.create(
name="Math Tutor",
instructions="You are a personal math tutor. Answer questions briefly, in a sentence or less.",
model="gpt-3.5-turbo",
)
# # 생성된 챗봇의 정보를 JSON 형태로 출력합니다.
print(assistant)
assistant_id=""
어시스턴트와 쓰레드는 독립(수학 과학 관련된 로봇과 관련없는 수학과 과학 관련된 카톡방) 일관성을 위해 하나의 주제에 맞는 어시스턴트에 하나의 주제에 맞는 쓰레드가 좋다
run을 사용할 때는 쓰레드와 어시스턴트가 독립적이기에 각각 아이디를 받아온다
status queued 대기중-비동기처리로 단계관리하기 위해->원하는 시점에 데이터를 받아 올 수 있다 completed 질문 답변 완료
list로 답변 확인
# 실행할 Run 을 생성합니다.
# Thread ID 와 Assistant ID 를 지정합니다.
run = client.beta.threads.runs.create(
thread_id="",
assistant_id="",
)
print(run)
run_id = run.id
while True:
run = client.beta.threads.runs.retrieve(
thread_id=thread_id,
run_id= run_id,
)
if run.status == "completed":
break
else:
time.sleep(2)
# print(run)
thread_messages = client.beta.threads.messages.list(thread_id)
print(thread_messages.data[0].content[0].text.value)
Assistants API
->chatgpt의 텍스트 형식의 도구의 제약을 해소하기 위해 탄생
code interpreter -디버깅과 다른 느낌 -토큰 제한수를 넘는 데이터를 위해 쿼리문을 작성해서 토큰을 효율적이게 사용 -쉽게 말해 엄청난 양의 데이터 분석 가능
retrieval -검색 -우리의 자료로 결과를 낼 수 있다 -문서를 gpt에게 학습을 시켜 그 문서를 토대로 답변을 해준다
function -내가 만든 함수를 기반으로 어시스턴트가 사용할 수 있게 만들어준다(예를들어 검색으로 학습한 문서를 기반으로 함수를 만들 수 있다)
Retreieval을 활용하여 이력서 학습을 시켜 나만의 챗봇 만들기
1. openai api 사이트에서 내가 만든 어시스턴트에 내 이력서 파일을 넣어준다(+추가로 instructions도 수정 가능)
from openai import OpenAI
import time
from flask import Flask, request, jsonify
from flask_cors import CORS
app = Flask(__name__)
CORS(app) # 모든 출처에서의 요청을 허용합니다.
# OpenAI API 키 설정
client = OpenAI(api_key="")
@app.route('/sendMessage', methods=['POST'])
def send_message():
data = request.get_json()
user_input = data.get('user_input')
try:
assistant_id=""
#resume thread
thread_id = ""
message = client.beta.threads.messages.create(
thread_id,
role="user",
content=user_input,
)
# 실행할 Run 을 생성합니다.
# Thread ID 와 Assistant ID 를 지정합니다.
run = client.beta.threads.runs.create(
thread_id=thread_id,
assistant_id=assistant_id,
)
run_id = run.id
while True:
run = client.beta.threads.runs.retrieve(
thread_id=thread_id,
run_id= run_id,
)
if run.status == "completed":
break
else:
time.sleep(2)
thread_messages = client.beta.threads.messages.list(thread_id)
ai_response = thread_messages.data[0].content[0].text.value
return jsonify({"description": ai_response})
except Exception as e:
return jsonify({"error": str(e)})
if __name__ == '__main__':
print("Flask 애플리케이션이 실행되었습니다.")
app.run(debug=True)
flask -백엔드의 전반적인 역활을 해준다 -웹페이지를 인터넷에 띄우고, 사용자들의 접속인 트래픽을 감당하고, 회원들의 정보와 게시판 정보를 관리하는 역활을 도와준다 - API 서버를 만드는 데에 특화 되어있는 Python Web Framework -URL을 파이썬 코드의 함수나 메서드에 매핑할 수 있는 라우팅 메커니즘을 제공
flask 기본 세팅
pip install Flask
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'he'
if __name__ == '__main__':
app.run(debug=True)
기본세팅 결과물
• 본인이 만든 파이썬코드 내용을 Flask에 이동시키기
from flask import Flask, request, jsonify
from flask_cors import CORS
from openai import OpenAI
import requests
import json
app = Flask(__name__)
CORS(app) # 모든 출처에서의 요청을 허용합니다.
# OpenAI API 키 설정
client = OpenAI(api_key="")
@app.route('/sendMessage', methods=['POST'])
def send_message():
data = request.get_json()
user_input = data.get('user_input')
try:
# OpenAI에 사용자 입력 전달하여 응답 받기
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": user_input}
]
)
ai_response = completion.choices[0].message.content.strip()
return jsonify({"description": ai_response})
except Exception as e:
return jsonify({"error": str(e)})
if __name__ == '__main__':
print("Flask 애플리케이션이 실행되었습니다.")
app.run(debug=True)
• localhost:5000/sendMessage API 만들기
-위 코드는 '/sendMessage' 엔드포인트에 POST 요청을 받으면 요청의 JSON 데이터에서 'message' 값을 읽어와 성공 응답을 반환한다.
4주차 기술과제 -API 토큰이 필요한 이유 코딩과제 -openai API 계정 생성 -파이썬에서 Openai 모듈 설치 -질문하고 답변 받아온거 print해서 테스트 해보기 -크롤링 한 데이터값을 GPT한테 주고 받은 답변을 Mysql에 저장하기
기술과제 *API 토큰이 필요한 이유 -API 토큰은 API를 사용할 때 인증 및 권한 부여를 위해 사용된다.
-이 토큰은 API를 호출할 때 서버가 클라이언트를 식별하고, 클라이언트가 특정 작업을 수행할 수 있는 권한이 있는지 확인하는 데 사용된다.
-따라서 API 토큰이 없으면 API를 사용할 수 없다.
-또한 API 토큰을 통해 API 사용량을 추적하고 제한할 수도 있다.
-이는 보안과 사용자 경험을 보장하기 위한 조치이다.
코딩과제 *openai API 계정 생성 *파이썬에서 Openai 모듈 설치
결제 안하면 작동 안된다
*질문하고 답변 받아온거 print해서 테스트 해보기
from openai import OpenAI
import re
client = OpenAI(api_key=".....")
# 사용자로부터 질문 입력 받기
user_input = input("질문을 입력하세요: ")
# 질문에 대한 대화 완성 생성
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": user_input}
]
)
# 답변 내용 가져오기
answer = completion.choices[0].message.content
# 문장으로 분리
sentences = re.split(r'(?<=[.!?]) +', answer)
# 4~5문장까지 선택하여 출력
print("답변:")
for sentence in sentences[:5]:
print(sentence)
*크롤링 한 데이터값을 GPT한테 주고 받은 답변을 Mysql에 저장하기
import pymysql
from bs4 import BeautifulSoup
import requests
from openai import OpenAI
# OpenAI API 키 설정
client = OpenAI(api_key="....")
# MySQL 데이터베이스 연결 설정
db_connection = pymysql.connect(host="localhost", user="root", password="....", db="rs", charset="utf8")
# MySQL 커서 생성
cursor = db_connection.cursor()
# 데이터 크롤링
data = requests.get('https://sports.news.naver.com/wfootball/index')
soup = BeautifulSoup(data.text, 'html.parser')
soccer_rank = soup.select('#_team_rank_epl > table > tbody > tr')
# 데이터를 담을 리스트 초기화
team_data = []
for tr in soccer_rank:
team_name = tr.select_one("td > div > div.info > span")
if team_name:
team_name = team_name.text.strip()
# GPT 모델에 전달하여 팀 설명 얻기
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": team_name}
]
)
team_description = completion.choices[0].message.content.strip()
team_data.append((team_name, team_description))
try:
# 축구팀 이름과 설명을 MySQL에 저장
query = "INSERT INTO my_schema.football_content2 (name, content) VALUES (%s, %s)"
cursor.executemany(query, team_data)
# 변경사항 저장
db_connection.commit()
print("데이터가 성공적으로 저장되었습니다.")
except Exception as e:
print("데이터 저장 중 오류가 발생하였습니다:", e)
finally:
# 연결 종료
cursor.close()
db_connection.close()
/list /detail /write /edit 위와 관련된 html을 서버가 준비 해뒀다가 클라이언트가 요청시 보내주는 게 mpa ->서버는 html페이지만 준비하고만 있으면 된다
mpa에 사용되는 언어: node js, pyhon, java, php, asp
*node.js가 무엇인가?
-웹서버 백엔드 구현을 하기 위해서 사용 -자바스크립트 영역이 서버쪽으로 확대되어 클라이언트와 서버 양쪽의 프로그램을 모두 개발이 가능해졌다.
백앤드 언어를 사용하는 이유: -언어와 데이터베이스를 연동을 시켜논다 -서버에서 필요한 데이터를 데이터베이스에서 가져와 html형식에 맞게 바꿔준다
*spa
-페이지가 하나 -페이지를 이동하지 않고 안에있는 컨텐츠만 바뀌어 깜빡임이 없다 -클라이언트가 서버에게 페이지 요청을 하면 빈 html파일을 준다+js소스파일을 준다(버튼을 누르면 js파일에 있는 소스 파일이 실행이되어 컨테츠만 바꿔준다)
*api
-약속 -버튼을 누르면(행동) 어떠한 동작이 되게하는 약속(ex자판기, 컴퓨터 자판...) -키보드 A누르면 A가 나오는 동작도 api -어떤 행위를 원할 때 이 버튼을 누르면 서버가 내가 원하는 동작을 해주는 약속 -spa에선 거의 API를 사용한다
-spa는 백앤드와 프로트앤드 서버가 따로 있다 -유지보수 측면에서 편하다 -백앤드는 API만 존재한다 -프론트엔드 서버한테 html과 js코드를 받아온다 그래서 데이터를 백엔드에 요청함 -장점:서버는 API만 제공하고 서버는 다양한 어플리케이션으로 사용할 수 있다.(HTTP만 가능하면)
*코드정리
app.js
constexpress=require('express');
constmysql=require('mysql');
constapp=express();
constport=4000;
constcors=require('cors');
app.use(cors());
constconn= {
host :'localhost',
port :'3306',
user :'root',
password :'----',
database :'my_schema'
};
letconnection=mysql.createConnection(conn);
connection.connect(); // db접속
app.engine('html', require('ejs').renderFile);
app.set('view engine', 'ejs');
app.get('/', (req, res) => {
res.render('index.html');
});
app.get('/list', (req, res) => {
connection.query('SELECT * from board', function(error, results, fields) {
if (error) throwerror;
console.log(results);
res.render('list',{'data':results})
});
});
app.get('/api/list', (req, res) => {
connection.query('SELECT * from board', function(error, results, fields) {