
-학습 데이터 (Xi, Yi)가 있을 때(i = 1,2,3,…N), 𝑌𝑖 ∈ −1, 1 (두 개의 클래스를 의미),
f(x)≥ 0, 𝑌𝑖 = +1
f(x)≤ 0, 𝑌𝑖 = −1
- Ex. Yi * f(Xi) > 0 라는 것은 제대로 분류된 형태 (같은 부호끼리 곱하면
양수인 경우니까)
선형분할
f(x)=W(기울기)TX+b
-선형분할은 직선으로 나누는 것 (2차원이건 3차원이건 그 이상이건 상관 없음)
-b(bias)는 Y 절편을 의미
-W는 직선의 기울기
-초평면:4차원이상
어떤 선이 좋은 판별선인가?
-딱 절반이면서
-여유로워야 한다->미래 대응 가능
최적의 분할 초평면은 ? (Optimal Separating Hyperplane)
• 최적 분할 초평면
✓ Margin을 최대화 시키는 초평면이 최적
✓ “Learning Theory”에 따르면, Margin을 최대화 시키는 초평면이 일반화 오류가 가장
낮게 나타남
✓ Margin: 초평면과 가장 근접한 각 클래스 관측치와의 거리의 합
max Margin = max 2/llwll = min llwll
• ||W||가 square root를 포함해서 미분이 어려움
• 분모와 분자를 바꿔서 Max문제를 Min 문제로 바꾸면 계산이 간편 !
• Norm을 그대로 쓰는것보다 제곱을 시켜서 표현(계산상 편이(루트 제거)!)
위에 불편한 점을 고려하여->min llwll = min llwll** =min 1/2llwll**
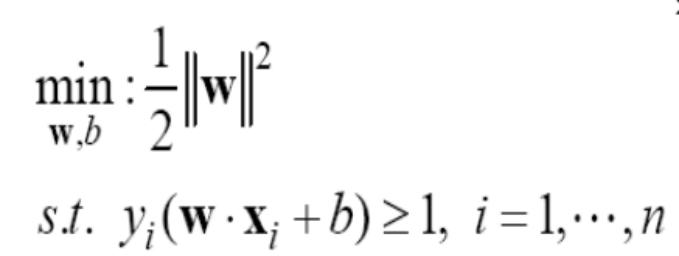
-Convex Optimization 이라는 문제 (최적해가 1개)
• Quadratic(2차) 목적함수와 선형 제약조건(+로 변수 조합)이 존재
• w, b는 의사결정변수, 결국 , w와b를 조절하여 목적함수를 최소화 !
• 제약조건의 의미 : y의 실제 레이블과 예측레이블이 곱이 1보단 커야함! (학습데이터를 완벽하게 나눈다는 조건!!!!)
• 중요한 포인트 : 목적함수는 마진을 늘리려 하고 제약조건은 마진을 줄이려고 함 (equilibrium)
-w와 b 가 결정변수
• 학습데이터가 선형식으로 완전히 나눌 수 있을 경우에만 해가 존재 (linearly
separable)
• 제약식이 있는 식에서 Lagrange Multiplier를 활용 다음과 같이 변환 가능
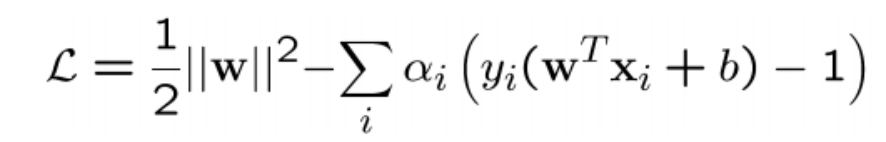
• 라그랑쥬 primal (min)과 dual (max)을 순차적으로 풀어서(α) 최종적으로는
W(직선의 기울기)를 결정 (어떻게? 각각 다 미분해서) !!=쌍대 문제
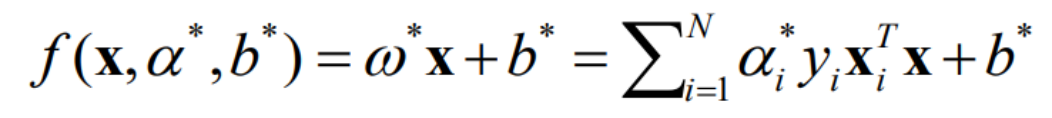
결국, 다음과 같은 식으로 정리됨 (판별식)
• 중요한 것은 α와 b와 xi(학습에 쓸 데이터)를 결정짓게 되면 자연스럽게 W(기울기)가 결정된다는 사실
• 이러한 형태를 선형 SVM(linear SVM)이라고 부름
• 저 식에 미래의 관측치(x)를 넣어서 1이면 class 1, -1이면 class -1
SVM (지지벡터머신)의 의미 정리
Support Vectors (마지노선)
• 모든 점을 활용하여 Hyper-plane을 얻는 것이 아니라 Support Vector만을
활용하여 얻음 (Sparse Representation(kNN 처럼))
만약에 선형으로 완벽히 나눠지지 않는 데이터라면?
->여유를 주자=soft margin
• Margin을 무조건 최대화 시키는 것보다는 (error + λ) / Margin을 최소화 시
키는 것은 어떨까? 라는 아이디어 (여기서 λ는 얼마나 에러를 허용할 지에 대
한 값)
• ξj는 허용 에러의 크기를 의미
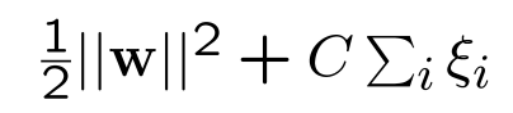
• C : trade-off 파라미터, 값이 크면 클수록 error를 많이 허용하게 되어 overfit
문제(too soft margin)가, 작으면 작을수록 hard margin이 됨 (underfit)
• C가 작을수록 원래 최적화 식이 중요해지므로, 마진이 커짐
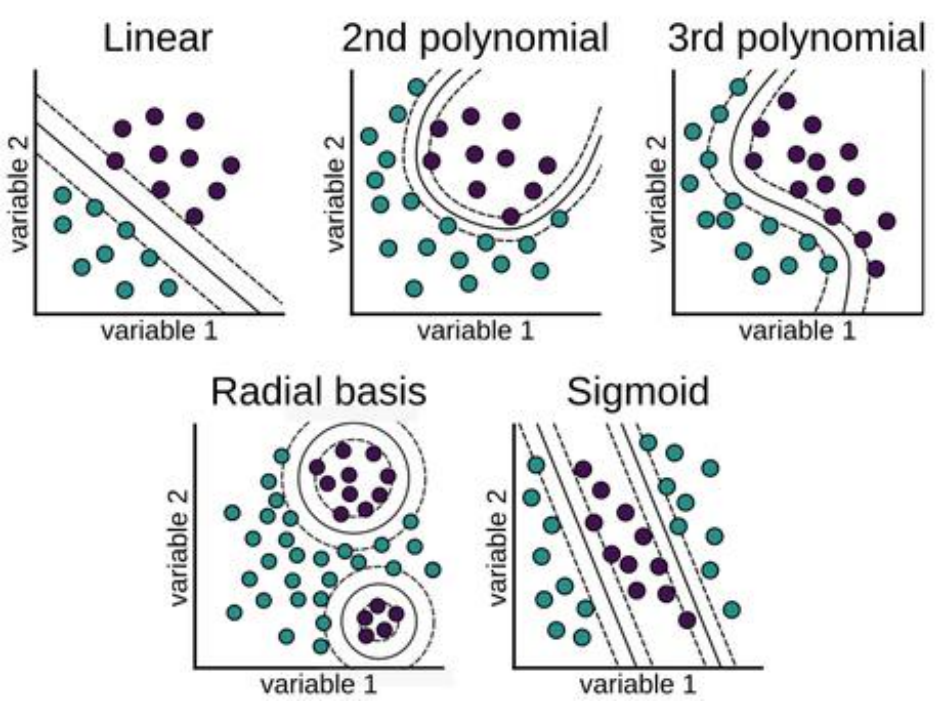
non-linear svm
• 커널(kernel) 트릭(K)을 통해 변환 가능 ! 직선 > 곡선, 혹은 다양한 형태로
• 보다 유연하게 데이터를 분류 가능함
• 저차원 공간에서 분리가 안되는 데이터를 고차원으로 매핑하려 분류 !
커널의 종류
-선형, 다항, 시그모이드, 가우시안 타입의 커널이 일반적으로 활용 (선형은 우
리가 배운것 !)
• 비선형 타입의 커널 활용으로 데이터의 분리가 보다 유연(Decision
boundary is flexible)
요약 및 의의
• SVM 갑자기 너무 어려운데 우리 왜 배웠을까 ?
- 머신러닝에서 활용하는 최적화의 기초 원리를 이해하기 위해
- 수학에 대한 면역력 확보
• SVM은 선을 그어 분류하는 것, 그렇기때문에 선을 구성하는 요소인 기울기
와 절편을 구해야 함
• 목적함수의 변경을 통해 모델을 업그레이드 할 수 있음
• 하이퍼파라미터 존재 (Kernel, Cost, ξ , …)
'Major > Data Analysis' 카테고리의 다른 글
| Modeling (Artificial Neural Network) & Deep Learning-2 (0) | 2024.06.17 |
|---|---|
| Modeling (Artificial Neural Network) & Deep Learning-1 (0) | 2024.06.17 |
| Decision Tree(의사결정나무) (0) | 2024.06.17 |
| KNN (0) | 2024.06.17 |
| Modeling & Validation & Visualization (2) | 2024.06.17 |