기초적인 함수 만들어 보기
> sum1ton = function(n){
+ result= sum(1:n)
+ return(result)
+ }
> sum1ton(100)
[1] 5050for/while(반복)
> i=0
> for (i in 1:10) {
+ print(i)
+ }
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
[1] 6
[1] 7
[1] 8
[1] 9
[1] 10
> number =1
> while (number<=10) {
+ print(number)
+ number = number+1
+ }
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
[1] 6
[1] 7
[1] 8
[1] 9
[1] 10
apply 반복문
반복문이 매우 귀찮은 경우가 존재->apply 사용
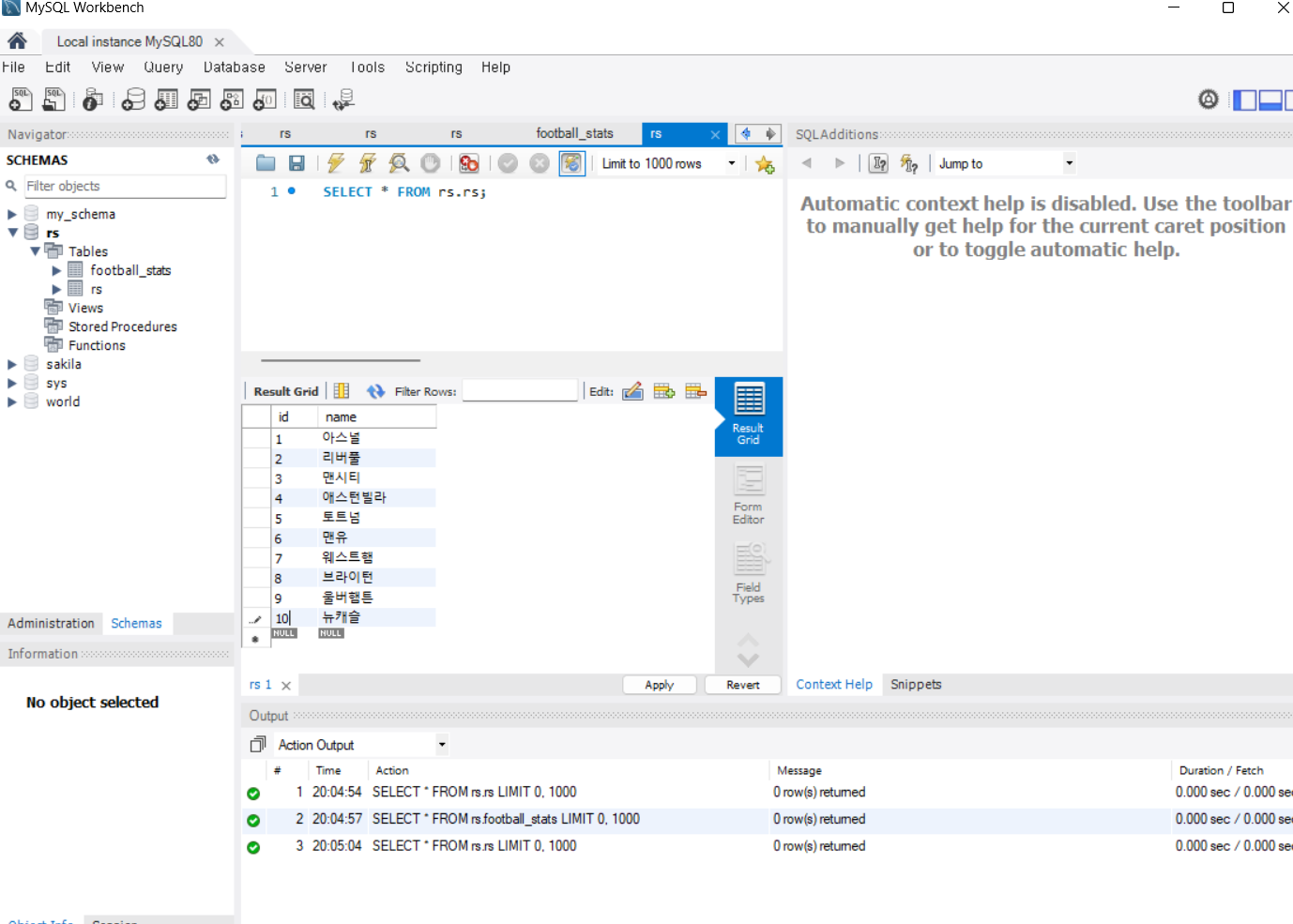
> a=matrix(1:12, nrow = 4, byrow = T)
> print(a)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
[4,] 10 11 12
> apply(a,MARGIN=1,FUN=sum)#margin 1은 rwo방향으로 더하라/ fun은 사용자 지정 함수수
[1] 6 15 24 33
> apply(a, 2, FUN=sum)#2는 col방향으로 다 더하라
[1] 22 26 30
array
> b=array(1:18, dim =c(3,3,2))#3*3배열열 2개
> b
, , 1
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
, , 2
[,1] [,2] [,3]
[1,] 10 13 16
[2,] 11 14 17
[3,] 12 15 18
> apply(b,3,diag)#3차원/diag 함수는 주어진 행렬의 주 대각선 요소를 반환하는 함수입니다
[,1] [,2]
[1,] 1 10
[2,] 5 14
[3,] 9 18
if/else(조건문)
> for (i in 1:10) {
+ if(i%%2==0){
+ print("짝수")
+ }
+ else{
+ print("홀수")
+ }
+ }
[1] "홀수"
[1] "짝수"
[1] "홀수"
[1] "짝수"
[1] "홀수"
[1] "짝수"
[1] "홀수"
[1] "짝수"
[1] "홀수"
[1] "짝수"
> x=3
> y= -5:5
> ifelse(x>y,1,0)
[1] 1 1 1 1 1 1 1 1 0 0 0-%%로 나누고 나머지가 0
-ifelse로 사람 카운팅 할 때 사용 가능
범죄현장 함수
-잘 안되네...
> site = c(1:10)
> x=c(2,5,5,5,1,5,7,4,5,6)
> y=c(0,4,1,2,8,9,5,2,4,1)
>
> name=c("a","b","c")
> axy=c(1,5,5)
> bxy=c(4,7,1)
> cxy=c(8,1,3)
> df=cbind(site,x,y)
> fix(df)
>
> df2=rbind(axy,bxy,cxy)
> fix(df2)
> site=df
>
> seller =axy[1:3]
> seller =bxy[1:3]
> seller =cxy[1:3]
>
> distance = function(seller,site){
+ dist_mat = matrix(0,10,1)
+ for (i in 1:10) {
+ temp = sqrt((seller-site[i,1:2])%*%t(t(seller-site[i,1:2])))
+ dist_mat[i,1] =temp
+ }
+ return(dist_mat)
+ }
>
> distance(seller,site[,2:3])
[,1]
[1,] 6.164414
[2,] 4.690416
[3,] 3.605551
[4,] 3.741657
[5,] 10.099505
[6,] 8.774964
[7,] 5.744563
[8,] 4.242641
[9,] 4.690416
[10,] 3.605551
20건의 경고들이 발견되었습니다 (이를 확인하기 위해서는 warnings()를 이용하시길 바랍니다).
> a=distance(seller, site/seller[3])
20건의 경고들이 발견되었습니다 (이를 확인하기 위해서는 warnings()를 이용하시길 바랍니다).
> b=distance(seller, site/seller[3])
20건의 경고들이 발견되었습니다 (이를 확인하기 위해서는 warnings()를 이용하시길 바랍니다).
> c=distance(seller, site/seller[3])
20건의 경고들이 발견되었습니다 (이를 확인하기 위해서는 warnings()를 이용하시길 바랍니다).
>
> dat = cbind(a,b,c)
>
> for(i in 1:10){
+ print(which.min(dat[i,]))
+ }
[1] 1
[1] 1
[1] 1
[1] 1
[1] 1
[1] 1
[1] 1
[1] 1
[1] 1
[1] 1
> if (identical(seller, axy)) {
+ distance(seller, site[, 2:3] / axy[3])
+ }
>
> if(seller==axy){
+ distance(seller, site[,2:3]/axy[3])
+ }-실패인듯