TCP와 UDP의 특징 및 차이점
7계층 중 전송 계층은 송신자와 수신자를 연결하는 통신 서비스를 제공하는 계층으로, 데이터의 전달을 담당한다.
데이터를 보내기 위해 사용하는 프로토콜에는 TCP와 UDP가 있다.

TCP (Transmission Control Protocol)
- 연결지향형 프로토콜: 데이터 전송 전 연결(논리적)을 설정하고, 데이터 전송 후 연결을 해제.
- 높은 신뢰성: 흐름제어, 혼잡제어, 오류검출 기능을 제공.
- 1:1 유니캐스트 통신: 단일 송신자와 단일 수신자 간의 통신을 지원.(멀티x)
UDP (User Datagram Protocol)
- 비연결형 프로토콜: 데이터 전송 전 연결 설정 없이 바로 전송.
- 빠른 속도: 데이터의 신속한 전송이 가능.
- 1:1, 1:다, 다:다 통신 가능: 브로드캐스트 및 멀티캐스트 지원.

TCP의 특징 및 구조
인터넷상에서 데이터를 메시지의 형태로 보내기 위해 IP와 함께 사용하는 프로토콜(논리적 경로)

+위 표 정보 외 추가 정보
*송신자와 수신자가 모두 소켓이라고 하는 종단점을 생성
*데이터 손실 등이 있을 경우 재전송 요청을 하므로 연속성있는 서비스에는 부적합 하다.
*전이중(full-duplex), 점대점(point-to-point) 방식이다.
- 전이중 : 전송이 양방향으로 동시에 일어날 수 있다.
- 점대점 : 각 연결이 정확히 2개의 종단점(소켓)을 가지고 있음을 의미한다.
TCP 헤더 구조
TCP 헤더는 데이터 전송의 신뢰성과 흐름제어, 혼잡제어를 위해 다양한 필드를 포함한다.


TCP 헤더의 크기
- 기본적으로 20bytes
- 옵션을 포함하면 최대 60bytes
발신지 포트와 목적지 포트 (16비트): 송수신 측의 포트 번호.
- port 번호와 함께 IP 헤더에 있는 source/destination address를 이용하여 유일한 식별되는 통신연결을 만들 수 있게 됨
- 크기는 각 16bit로, 0~65536 사이의 포트번호를 표시한다.
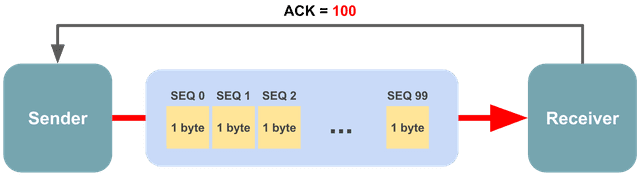
시퀀스 번호 (32비트): 데이터의 순서를 나타내며, 수신자가 데이터 조립 시 사용.
- 32bit를 할당받음
- 이 시퀀스 번호 덕분에, 수신자는 쪼개진 세그먼트의 순서를 파악해 순서 및 도착을 보장
- 최초로 데이터를 전송할 때는 랜덤한 수로 초기화를 시키고 보낼 데이터의 1byte(8bit)당 시퀀스 번호를 1씩 증가시키며 데이터의 순서를 표현
- 쵀대 4,294,967,296까지 수를 담을 수 있으며, 넘어갈 경우 다시 0부터 시작
승인 번호 (32비트): 다음에 수신할 데이터의 시퀀스 번호.
- 32bit를 할당받음
- 연결 설정과 해제 시 발생하는 핸드쉐이크 과정에는 상대방이 보낸 시퀀스 번호 + 1(다음 시퀸스 번호)
- 실제로 데이터를 주고 받을 때는 상대방이 보낸 시퀀스 번호 + 자신이 받은 데이터의 bytes
데이터 오프셋 (4비트): 데이터가 시작하는 위치.
- 전체 세그먼트 중에서 헤더가 아닌 데이터가 시작되는 위치가 어디부터인지를 표시 (옵션 필드의 길이가 고정되어 있지 않기 때문에 필요한 필드)
- 이 오프셋을 표기할 때는 32비트 워드 단위 사용. (1word = 4bytes) 이 필드 값에 4를 곱하면 세그먼트의 헤더를 제외한 실제 데이터의 시작 위치를 알 수 있음
- 4bit를 할당 받음. 0000~1111 범위를 표현할 수 있으므로 0~15 word * 4bytes로 0~60bytes의 오프셋까지 표현할 수 있음. 단, 옵션 필드를 제외한 나머지 필드는 필수로 존재해야하기 때문에 최솟값은 20bytes(5 word)로 고정
예약 필드 (3비트): 미래를 위한 예약 필드.
- 3bit를 할당받음. 000으로 찍힘
플래그 비트 (9비트): 세그먼트의 속성.
*Flag: 무엇인가를 기억해야 하거나 또는 다른 프로그램에게 약속된 신호를 남기기 위한 용도로 프로그램에서 사용되는 미리 정의된 비트를 의미합니다.
*패킷: 인터넷 내에서 데이터를 보내기 위한 경로배정(라우팅)을 효율적으로 하기 위해서 데이터를 여러 개의 조각들로 나누어 전송을 하는데 이때, 이 조각을 패킷이라고 한다.
SYN: 연결 설정.
- TCP에서 세션을 성립할 때(연결) 가장 먼저 보내는 패킷. 시퀀스 번호를 임의로 설정하여 세션을 연결하는데 사용되며 초기에 시퀀스 번호를 보내게 된다.
ACK: 승인 번호 유효.
- 상대방으로부터 패킷을 받았다는 것을 알려주는 패킷으로, 다른 Flag와 같이 출력되는 경우도 있다. 송신 측에서 수신 측 시퀀스 번호에 TCP 계층에서 길이 또는 데이터 양을 더한 것과 같은 ACK를 보낸다. (일반적으로 +1을 하여 보 냅니다) ACK 응답을 통해 보낸 패킷에 대한 성공, 실패를 판단하여 재전송 하거나 다음 패킷을 전송한한다.
FIN: 연결 종료.
- 세션 연결을 종료시킬 때 사용되며, 더이상 전송할 데이터가 없음을 나타낸다.
RST: 연결 재설정.
- 재설정(Reset)을 하는 과정이며 양방향에서 동시에 일어나는 중단 작업. 비정상적인 세션 연결 끊기에 해당한다. 이 패킷을 보내는 곳이 현재 접속하고 있는 곳과 즉시 연결을 끊고자 할 때 사용한다.
PSH: 즉시 전달.
- 버퍼가 채워지기를 기다리지 않고 데이터를 받는 즉시 전달하는 Flag. 데이터는 버퍼링 없이 OSI 7 Layer Application Layer의 응용프로그램으로 바로 전달한다.
URG: 긴급 데이터.
- 긴급한 데이터의 우선순위를 다른 데이터의 우선순위보다 높여 긴급하게 데이터를 전달하는 Flag.
NS, CWR, ECE: 혼잡 제어.
- 전문성이 높고 사용 빈도도 적어 간단하게 혼잡 제어에 사용된다고만 이해하자
윈도우 크기 (16비트): 한번에 수신할 수 있는 데이터의 양. 흐름제어의 기능을 담당.
체크섬 (16비트): 오류 검출.
- 데이터를 송신하는 중에 발생할 수 있는 오류를 검출하기 위한 값
- 송신 측에서 전송할 데이터를 16bit씩 나눠 Warp Around 방식으로 차례로 더한 값의 1의 보수 값을 체크섬 값으로 지정한다.
- 수신 측은 데이터를 받아 동일한 방식으로 값을 더해 1의 보수를 취하지 않은 값과 체크섬을 더하여 모든 비트가 1인지 확인한다. (모든 비트가 1이면 데이터가 정상이라고 판단)
긴급 포인터 (16비트): 긴급 데이터의 시작 위치.
- 일반 데이터 내에서 긴급 데이터가 시작되는 위치 정보
- URG 플래그가 1이라면 수신 측은 이 포인터가 가리키고 있는 데이터를 우선 처리
옵션 (가변 길이): TCP 확장 기능.
- TCP의 기능을 확장할 때 사용하는 필드들이며, 이 필드는 크기가 고정된 것이 아니라 가변적
- 옵션을 모두 사용했을 때 옵션 필드의 최대 길이는 40byte다.(->총 20byte+40byte=60byte)
- Data offset필드가 옵션 필드의 끝을 가리키는데, 실제 옵션 필드의 끝 < Data offset라면 부족한 부분만큼 0으로 채워야함
- 대표적인 옵션으로는 윈도우 사이즈의 확장을 위한 WSCALE, Selective Repeat 방식을 사용하기 위한 SACK 등이 있음
- 약 30개 정도의 옵션을 사용할 수 있음
TCP 연결 방식 (3-Way Handshaking)
TCP는 장치들 사이에 논리적인 접속을 성립(establish)하기 위하여 3-Way Handshaking를 사용한다.
3-Way Handshake의 역할은 양쪽 모두 데이터를 전송할 준비가 되었다는 것을 보장하는 것이다.
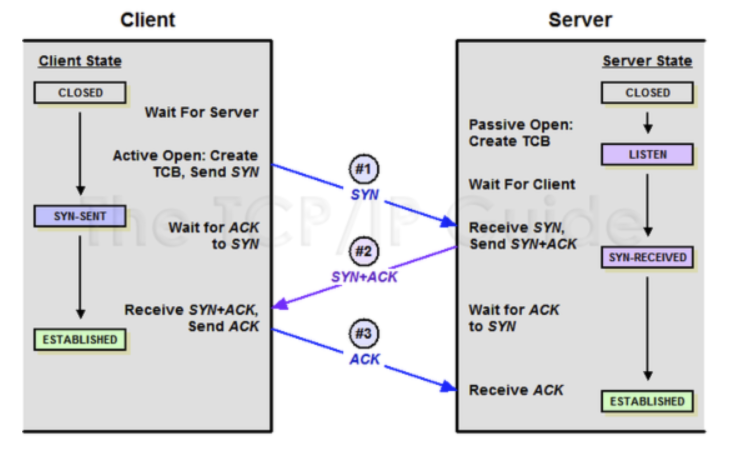
1. SYN 패킷 전송 (클라이언트 → 서버)
- 클라이언트는 서버에 접속을 요청하기 위해 SYN(Synchronize Sequence Numbers) 패킷을 보낸다.
- 이때 클라이언트는 SYN_SENT 상태가 되며, 서버의 응답을 기다린다.
2. SYN/ACK 패킷 전송 (서버 → 클라이언트)
- 서버는 클라이언트의 SYN 요청을 받고, 이를 수락한다는 의미로 SYN과 ACK(Acknowledgment) 플래그가 설정된 패킷을 클라이언트에게 보낸다.
- 이때 서버는 SYN_RECEIVED 상태가 된다.
3. ACK 패킷 전송 (클라이언트 → 서버)
- 클라이언트는 서버의 SYN/ACK 패킷을 받고, 이를 확인했다는 의미로 ACK 패킷을 서버에 보낸다.
- 이때 연결이 성립되며, 서버는 ESTABLISHED 상태가 된다.
- 이제 클라이언트와 서버는 데이터를 주고받을 수 있다.
TCP 연결 해제 방식 (4-Way Handshaking)
반대로 TCP 연결을 종료하는 과정은 4-Way Handshake로 이루어진다.
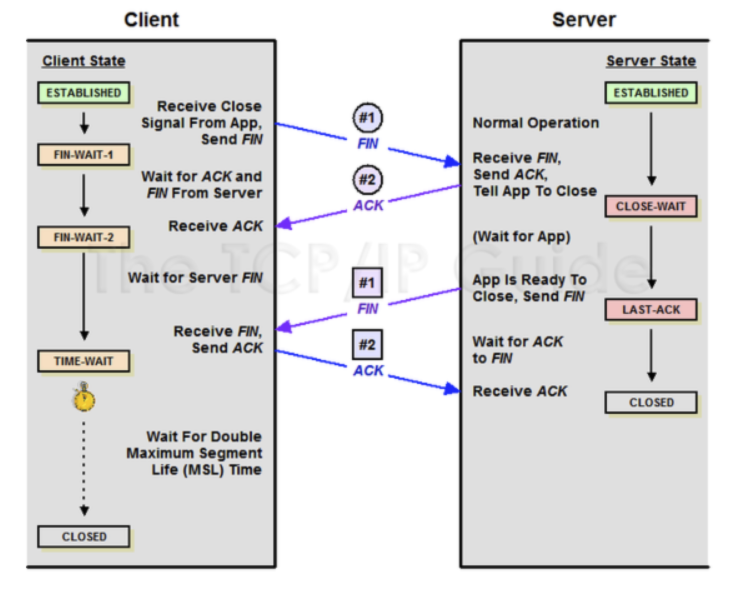
1. 클라이언트 → 서버: FIN 패킷 전송
- 클라이언트는 연결을 종료하고자 할 때 FIN(Finish) 플래그가 설정된 패킷을 서버에 보낸다.
- 이때 클라이언트는 연결 종료를 대기하는 상태가 된다.
2. 서버 → 클라이언트: ACK 패킷 전송
- 서버는 클라이언트의 FIN 패킷을 받고, 이를 정상적으로 받았다는 의미로 ACK(Acknowledgment) 패킷을 클라이언트에 보낸다.
- 서버는 CLOSE-WAIT 상태가 된다.
3. 서버 → 클라이언트: FIN 패킷 전송
- 서버는 연결을 종료한 후, 클라이언트에게 FIN 플래그가 설정된 패킷을 보낸다.
4. 클라이언트 → 서버: ACK 패킷 전송
- 클라이언트는 서버의 FIN 패킷을 받고, 이를 확인했다는 의미로 ACK 패킷을 서버에 보낸다.
- 클라이언트는 일정 시간 동안 TIME-WAIT 상태가 되어 서버의 재전송 패킷을 기다린다.
5. 서버: 세션 종료
- 서버는 클라이언트로부터 ACK 패킷을 받은 후 소켓을 닫고, 두 TCP 간의 세션이 종료된다.
6. 클라이언트: TIME-WAIT 상태
- TIME-WAIT 상태에 있는 클라이언트는 일정 시간 동안 세션을 유지하며 도착하지 않은 패킷을 기다린다.
- 서버에서 FIN을 전송하기 전에 전송한 패킷이 늦게 도착할 경우, 클라이언트는 서버로부터 FIN을 수신한 후에도 일정 시간 동안(기본 240초) 세션을 유지하며 잉여 패킷을 기다리는 TIME-WAIT 상태에 머물러 데이터 유실을 방지한다.
- 일정 시간이 지나면 클라이언트도 소켓을 닫고 세션을 완전히 종료한다.
TCP 재전송과 타임아웃
클라이언트는 일정 시간 내에 서버의 확인 응답(ACK)을 받지 못하면 패킷을 재전송하여 데이터 유실을 방지한다.
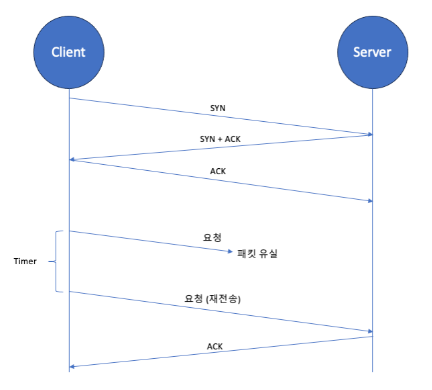
재전송: 데이터 전송 후 응답 패킷 미수신 시 재전송.
타임아웃 (RTO): 응답 패킷 대기 시간. 너무 짧으면 재전송, 너무 길면 속도 저하.
- 패킷 전송 및 확인: 클라이언트가 서버로 데이터 패킷을 전송하고, 서버는 이를 확인(ACK)하는 응답 패킷을 보낸다.
- 타이머 시작: 클라이언트는 패킷을 전송한 후 타이머를 시작한다. 일정 시간 내에 서버로부터 확인 응답(ACK)을 받지 못하면 타이머가 만료된다.
- 패킷 유실 감지 및 재전송: 클라이언트가 타이머 만료를 감지하면 해당 패킷이 유실된 것으로 간주하고 동일한 패킷을 다시 전송한다.
- 서버의 응답: 서버는 재전송된 패킷을 수신하고, 이를 확인하는 응답(ACK)을 다시 클라이언트에게 보낸다.
- 타이머 초기화 및 재시작: 클라이언트는 서버로부터 응답을 받으면 타이머를 초기화하고 다시 시작한다. 이는 다음 패킷에 대해 동일한 과정을 반복한다.
UDP의 특징 및 구조
데이터를 데이터그램(독립적인 관계를 지니는 패킷) 단위로 처리하는 프로토콜(논리x)
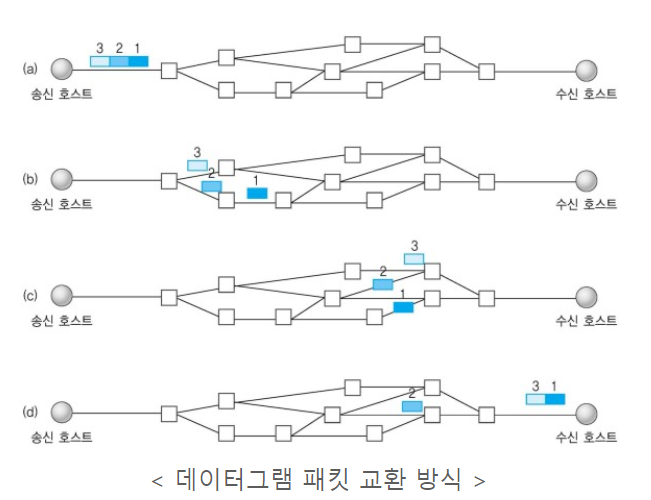
+위 표 정보 외 추가 정보
*흐름제어(flow control), 오류제어, 손상된 세크먼드의 수신에 대한 재전송 X
*포트들을 사용하여 IP 프로토콜에 인터페이스를 제공하는 역할을 수행한다.
*요청 또는 응답이 손실된다면 재전송 없이 단지 타임아웃 처리되고, 다시 시도하면 된다.
*코드가 간단하고 초기설정이 TCP와 비교하여 적은 메시지를 요구한다.
*연결 자체가 없어 소켓 구분이 없고, 소켓 대신 IP를 기반으로 데이터를 전송한다.
UDP 헤더 구조
UDP는 단순한 데이터 전송을 위해 설계되어 헤더가 간단하다.
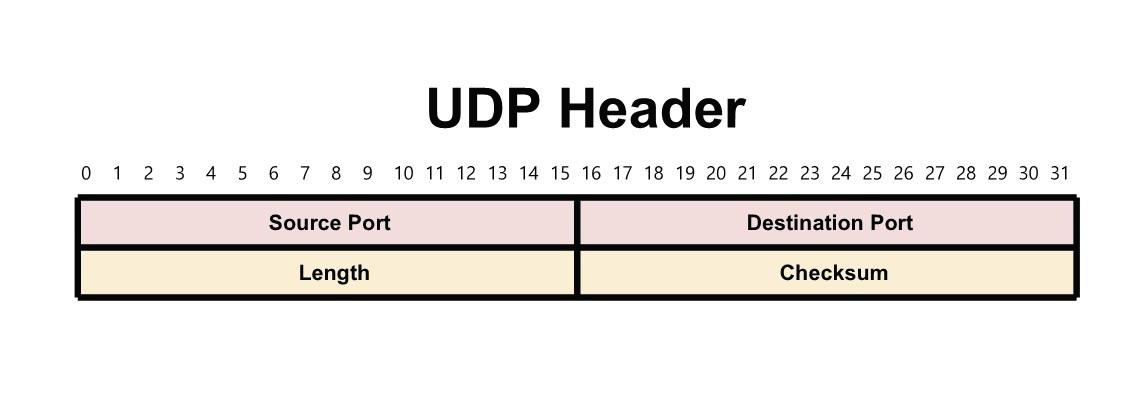
UDP 헤더의 크기
- 8bytes
발신지 포트와 목적지 포트 (16비트): 송수신 측의 포트 번호.
길이 (16비트): 헤더와 데이터의 총 길이.
체크섬 (16비트, 선택적): 오류 검출. TCP와 달리 필수는 아님.
- 체크섬은 데이터 전송 중 발생할 수 있는 오류를 검출하기 위해 사용되지만 TCP와 달리 UDP는 오류 복구 기능을 제공하지 않아 오류 검출 후의 처리는 응용 프로그램에서 담당해야 한다.
UDP 통신 방식
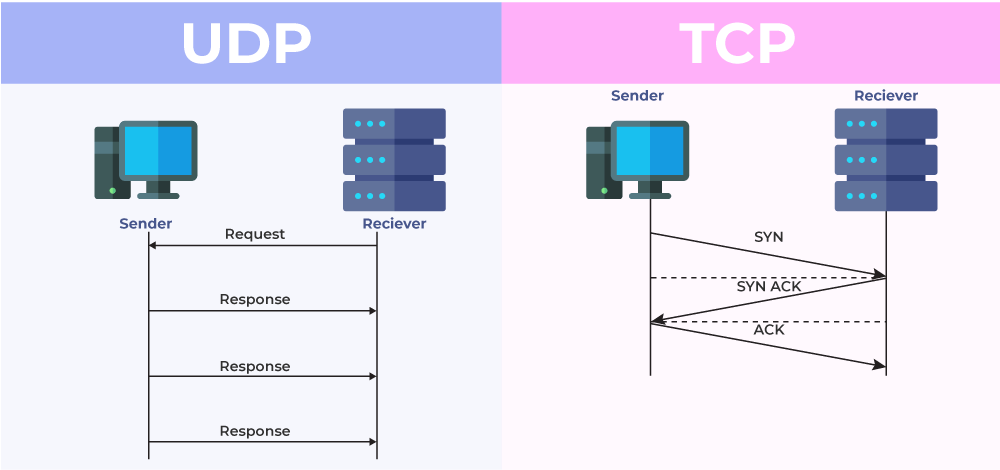
- 수신자의 수신 여부 확인 없이 데이터 전송.
- 빠른 데이터 전송이 필요할 때 유용.
- 브로드캐스트 및 멀티캐스트 지원.
결론(TCP와 UDP의 용도)
- TCP는 신뢰성이 중요한 웹 페이지 로드, 이메일 전송, 파일 전송 등의 애플리케이션에 적합하다.
- UDP는 실시간 스트리밍, 온라인 게임, VoIP 등 빠른 데이터 전송이 중요한 애플리케이션에 적합하다.


*PPT
*참고자료
https://bellog.tistory.com/235
https://ohcodingdiary.tistory.com/7
https://ohcodingdiary.tistory.com/12
https://evan-moon.github.io/2019/11/10/header-of-tcp/
https://github.com/yeoseon/tip-archive/issues/90
'Security > Network' 카테고리의 다른 글
| Firewall, DDoS, IDS 와 IPS 의 특징 및 차이점 (0) | 2024.08.24 |
|---|---|
| 계층별 주요 프로토콜(2) (0) | 2024.08.12 |
| 계층별 주요 프로토콜(1) (0) | 2024.08.10 |
| OSI 계층 별 장비 (2) | 2024.07.23 |
| OSI 7 Layer (1) | 2024.07.16 |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}